Semi-Supervised 3D Hand-Object Poses Estimation with Interactions in Time

PubDate: Jun 2021
Teams: UC San Diego;NVIDIA
Writers: Shaowei Liu, Hanwen Jiang, Jiarui Xu, Sifei Liu, Xiaolong Wang
PDF: Semi-Supervised 3D Hand-Object Poses Estimation with Interactions in Time

Abstract
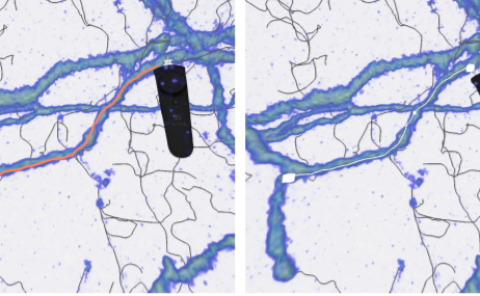
Estimating 3D hand and object pose from a single image is an extremely challenging problem: hands and objects are often self-occluded during interactions, and the 3D annotations are scarce as even humans cannot directly label the ground-truths from a single image perfectly. To tackle these challenges, we propose a unified framework for estimating the 3D hand and object poses with semi-supervised learning. We build a joint learning framework where we perform explicit contextual reasoning between hand and object representations by a Transformer. Going beyond limited 3D annotations in a single image, we leverage the spatial-temporal consistency in large-scale hand-object videos as a constraint for generating pseudo labels in semi-supervised learning. Our method not only improves hand pose estimation in challenging real-world dataset, but also substantially improve the object pose which has fewer ground-truths per instance. By training with large-scale diverse videos, our model also generalizes better across multiple out-of-domain datasets. Project page and code: this https URL