How You Move Your Head Tells What You Do: Self-supervised Video Representation Learning with Egocentric Cameras and IMU Sensors

PubDate: Oct 2021
Teams: Indiana University;Facebook Reality Labs
Writers: Satoshi Tsutsui, Ruta Desai, Karl Ridgeway
Abstract
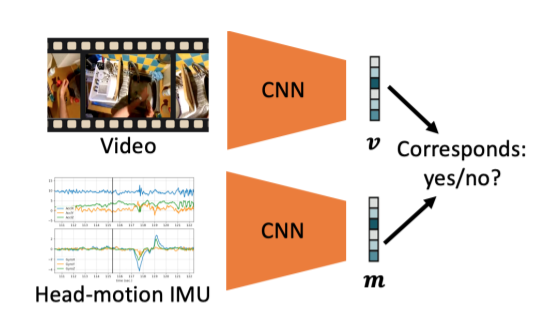
Understanding users’ activities from head-mounted cameras is a fundamental task for Augmented and Virtual Reality (AR/VR) applications. A typical approach is to train a classifier in a supervised manner using data labeled by humans. This approach has limitations due to the expensive annotation cost and the closed coverage of activity labels. A potential way to address these limitations is to use self-supervised learning (SSL). Instead of relying on human annotations, SSL leverages intrinsic properties of data to learn representations. We are particularly interested in learning egocentric video representations benefiting from the head-motion generated by users’ daily activities, which can be easily obtained from IMU sensors embedded in AR/VR devices. Towards this goal, we propose a simple but effective approach to learn video representation by learning to tell the corresponding pairs of video clip and head-motion. We demonstrate the effectiveness of our learned representation for recognizing egocentric activities of people and dogs.
