AvatarPoser: Articulated Full-Body Pose Tracking from Sparse Motion Sensing

PubDate: Jul 2022
Teams: ETH Zurich;Reality Labs
Writers: Jiaxi Jiang, Paul Streli, Huajian Qiu, Andreas Fender, Larissa Laich, Patrick Snape, Christian Holz
PDF: AvatarPoser: Articulated Full-Body Pose Tracking from Sparse Motion Sensing
Abstract
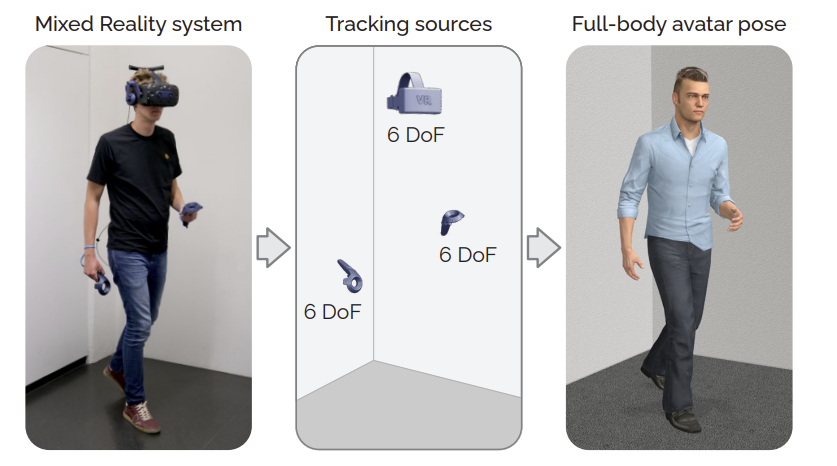
Today’s Mixed Reality head-mounted displays track the user’s head pose in world space as well as the user’s hands for interaction in both Augmented Reality and Virtual Reality scenarios. While this is adequate to support user input, it unfortunately limits users’ virtual representations to just their upper bodies. Current systems thus resort to floating avatars, whose limitation is particularly evident in collaborative settings. To estimate full-body poses from the sparse input sources, prior work has incorporated additional trackers and sensors at the pelvis or lower body, which increases setup complexity and limits practical application in mobile settings. In this paper, we present AvatarPoser, the first learning-based method that predicts full-body poses in world coordinates using only motion input from the user’s head and hands. Our method builds on a Transformer encoder to extract deep features from the input signals and decouples global motion from the learned local joint orientations to guide pose estimation. To obtain accurate full-body motions that resemble motion capture animations, we refine the arm joints’ positions using an optimization routine with inverse kinematics to match the original tracking input. In our evaluation, AvatarPoser achieved new state-of-the-art results in evaluations on large motion capture datasets (AMASS). At the same time, our method’s inference speed supports real-time operation, providing a practical interface to support holistic avatar control and representation for Metaverse applications.

