Self-Supervised Human Depth Estimation From Monocular Videos

PubDate: May 2020
Teams: Simon Fraser University;Nanjing University;ETH Zurich;Alibaba AI Labss
Writers: Feitong Tan Hao Zhu Zhaopeng Cui Siyu Zhu Marc Pollefeys Ping Tan
PDF: Self-Supervised Human Depth Estimation From Monocular Videos
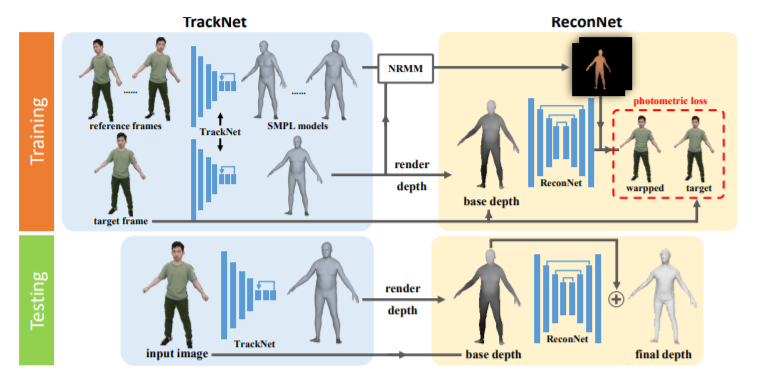
Abstract
Previous methods on estimating detailed human depth often require supervised training with `ground truth’ depth data. This paper presents a self-supervised method that can be trained on YouTube videos without known depth, which makes training data collection simple and improves the generalization of the learned network. The self-supervised learning is achieved by minimizing a photo-consistency loss, which is evaluated between a video frame and its neighboring frames warped according to the estimated depth and the 3D non-rigid motion of the human body. To solve this non-rigid motion, we first estimate a rough SMPL model at each video frame and compute the non-rigid body motion accordingly, which enables self-supervised learning on estimating the shape details. Experiments demonstrate that our method enjoys better generalization and performs much better on data in the wild.

