RAFT-3D: Scene Flow using Rigid-Motion Embeddings

PubDate: June 2021
Teams: Princeton University
Writers: Zachary Teed;Jia Deng
PDF: RAFT-3D: Scene Flow using Rigid-Motion Embeddings
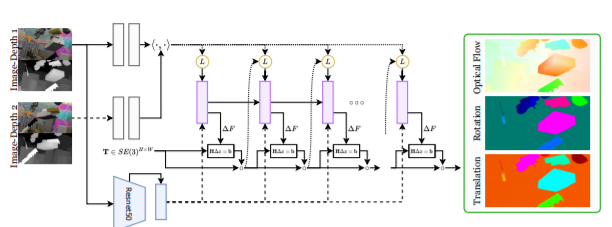
Abstract
We address the problem of scene flow: given a pair of stereo or RGB-D video frames, estimate pixelwise 3D motion. We introduce RAFT-3D, a new deep architecture for scene flow. RAFT-3D is based on the RAFT model developed for optical flow but iteratively updates a dense field of pixelwise SE3 motion instead of 2D motion. A key innovation of RAFT-3D is rigid-motion embeddings, which represent a soft grouping of pixels into rigid objects. Integral to rigid-motion embeddings is Dense-SE3, a differentiable layer that enforces geometric consistency of the embeddings. Experiments show that RAFT-3D achieves state-ofthe-art performance. On FlyingThings3D, under the twoview evaluation, we improved the best published accuracy (δ < 0.05) from 34.3% to 83.7%. On KITTI, we achieve an error of 5.77, outperforming the best published method (6.31), despite using no object instance supervision.

