Adaptive Multi-Channel Signal Enhancement Based on Multi-Source Contribution Estimation

PubDate: August 23, 2021
Teams: Facebook Reality Labs Research
Writers: Jacob Donley, Vladimir Tourbabin, Boaz Rafaely, Ravish Mehra
PDF: Adaptive Multi-Channel Signal Enhancement Based on Multi-Source Contribution Estimation
Abstract
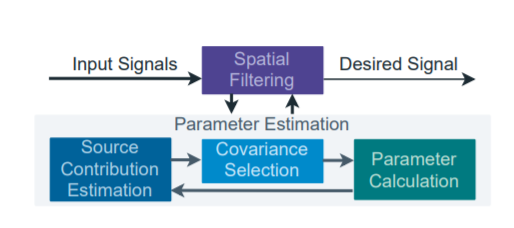
Automated solutions to multi-channel signal enhancement for improving speech communication in noisy environments has become a popular goal among the research community. Many proposed approaches focus on adapting to speech signals based on their temporal characteristics but these methods are primarily limited to specific types of desired and undesired sound sources. This paper outlines a new method to adapt to desired and undesired signals using their spatial statistics, independent of their temporal characteristics. The method uses a linearly constrained minimum variance (LCMV) beamformer to estimate the relative source contribution of each source in a mixture, which is then used to weight statistical estimates of the spatial characteristics of each source used for final separation. The proposed method allows for instantaneous desired and undesired source selection, a useful ability for the enhancement of conversations. The simulated results show that the method can adapt to the targeted source in noisy mixture signals and that under realistic conditions it is also capable of reaching ideal MVDR performance.