DVD: A Diagnostic Dataset for Multi-step Reasoning in Video Grounded Dialogue

PubDate: October 1, 2021
Teams: Singapore Management University;Institute for Infocomm Research
Writers: Hung Le, Chinnadhurai Sankar, Seungwhan Moon, Ahmad Beirami, Alborz Geramifard, Satwik Kottur
PDF: DVD: A Diagnostic Dataset for Multi-step Reasoning in Video Grounded Dialogue
Abstract
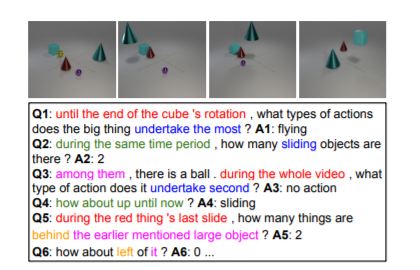
A video-grounded dialogue system is required to understand both dialogue, which contains semantic dependencies from turn to turn, and video, which contains visual cues of spatial and temporal scene variations. Building such dialogue systems is a challenging problem, involving various reasoning types on both visual and language inputs. Existing benchmarks do not have enough annotations to thoroughly analyze dialogue systems and understand their capabilities and limitations in isolation. These benchmarks are also not explicitly designed to minimise biases that models can exploit without actual reasoning. To address these limitations, in this paper, we present DVD, a Diagnostic Dataset for Videogrounded Dialogues. The dataset is designed to contain minimal biases and has detailed annotations for the different types of reasoning over the spatio-temporal space of video. Dialogues are synthesized over multiple question turns, each of which is injected with a set of cross-turn semantic relationships. We use DVD to analyze existing approaches, providing interesting insights into their abilities and limitations. In total, DVD is built from 11k CATER synthetic videos and contains 10 instances of 10-round dialogues for each video, resulting in more than 100k dialogues and 1M question-answer pairs. Our code and dataset are publicly available: GitHub