Anticipative Video Transformer

PubDate: October 1, 2021
Teams: Facebook AI Research;University of Texas
Writers: Rohit Girdhar, Kristen Grauman
PDF: Anticipative Video Transformer
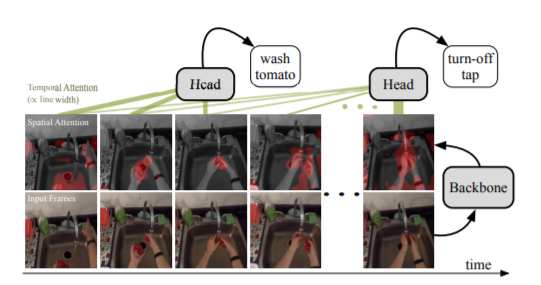
Abstract
We propose Anticipative Video Transformer (AVT), an end-to-end attention-based video modeling architecture that attends to the previously observed video in order to anticipate future actions. We train the model jointly to predict the next action in a video sequence, while also learning frame feature encoders that are predictive of successive future frames’ features. Compared to existing temporal aggregation strategies, AVT has the advantage of both maintaining the sequential progression of observed actions while still capturing long-range dependencies—both critical for the anticipation task. Through extensive experiments, we show that AVT obtains the best reported performance on four popular action anticipation benchmarks: EpicKitchens-55, EpicKitchens-100, EGTEA Gaze+, and 50-Salads; and it wins first place in the EpicKitchens-100 CVPR’21 challenge. Project page: GitHub

