Semantic-Aware Implicit Neural Audio-Driven Video Portrait Generation

PubDate: Jan 2022
Teams: The Chinese University of Hong Kong;Monash University;SenseTime Research
Writers: Xian Liu, Yinghao Xu, Qianyi Wu, Hang Zhou, Wayne Wu, Bolei Zhou
PDF: Semantic-Aware Implicit Neural Audio-Driven Video Portrait Generation
Abstract
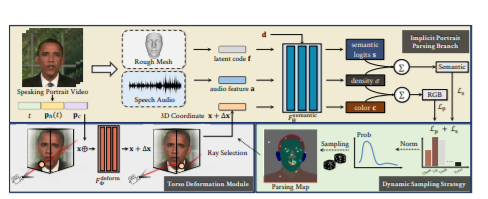
Animating high-fidelity video portrait with speech audio is crucial for virtual reality and digital entertainment. While most previous studies rely on accurate explicit structural information, recent works explore the implicit scene representation of Neural Radiance Fields (NeRF) for realistic generation. In order to capture the inconsistent motions as well as the semantic difference between human head and torso, some work models them via two individual sets of NeRF, leading to unnatural results. In this work, we propose Semantic-aware Speaking Portrait NeRF (SSP-NeRF), which creates delicate audio-driven portraits using one unified set of NeRF. The proposed model can handle the detailed local facial semantics and the global head-torso relationship through two semantic-aware modules. Specifically, we first propose a Semantic-Aware Dynamic Ray Sampling module with an additional parsing branch that facilitates audio-driven volume rendering. Moreover, to enable portrait rendering in one unified neural radiance field, a Torso Deformation module is designed to stabilize the large-scale non-rigid torso motions. Extensive evaluations demonstrate that our proposed approach renders more realistic video portraits compared to previous methods. Project page: this https URL