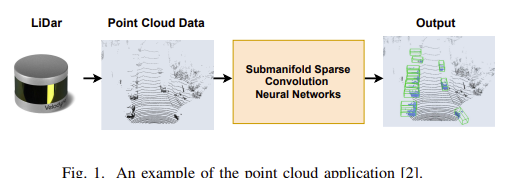
An Efficient FPGA Accelerator for Point Cloud

PubDate: Otc 2022
Teams: Nanjing University
Writers: Zilun Wang, Wendong Mao, Peixiang Yang, Zhongfeng Wang, Jun Lin
PDF: An Efficient FPGA Accelerator for Point Cloud
Abstract
Deep learning-based point cloud processing plays an important role in various vision tasks, such as autonomous driving, virtual reality (VR), and augmented reality (AR). The submanifold sparse convolutional network (SSCN) has been widely used for the point cloud due to its unique advantages in terms of visual results. However, existing convolutional neural network accelerators suffer from non-trivial performance degradation when employed to accelerate SSCN because of the extreme and unstructured sparsity, and the complex computational dependency between the sparsity of the central activation and the neighborhood ones. In this paper, we propose a high performance FPGA-based accelerator for SSCN. Firstly, we develop a zero removing strategy to remove the coarse-grained redundant regions, thus significantly improving computational efficiency. Secondly, we propose a concise encoding scheme to obtain the matching information for efficient point-wise multiplications. Thirdly, we develop a sparse data matching unit and a computing core based on the proposed encoding scheme, which can convert the irregular sparse operations into regular multiply-accumulate operations. Finally, an efficient hardware architecture for the submanifold sparse convolutional layer is developed and implemented on the Xilinx ZCU102 field-programmable gate array board, where the 3D submanifold sparse U-Net is taken as the benchmark. The experimental results demonstrate that our design drastically improves computational efficiency, and can dramatically improve the power efficiency by 51 times compared to GPU.