Predict-and-Critic: Accelerated End-to-End Predictive Control for Cloud Computing through Reinforcement Learning

PubDate: Dec 2022
Teams: University of Pennsylvania;AWS AI Labs
Writers: Kaustubh Sridhar, Vikramank Singh, Balakrishnan Narayanaswamy, Abishek Sankararaman
Abstract
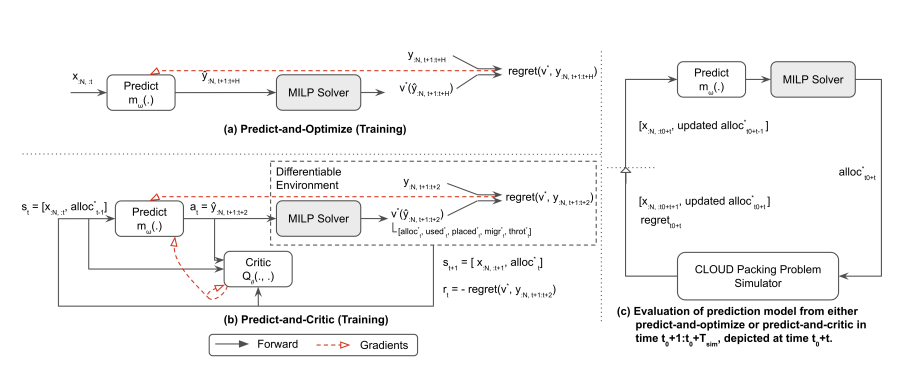
Cloud computing holds the promise of reduced costs through economies of scale. To realize this promise, cloud computing vendors typically solve sequential resource allocation problems, where customer workloads are packed on shared hardware. Virtual machines (VM) form the foundation of modern cloud computing as they help logically abstract user compute from shared physical infrastructure. Traditionally, VM packing problems are solved by predicting demand, followed by a Model Predictive Control (MPC) optimization over a future horizon. We introduce an approximate formulation of an industrial VM packing problem as an MILP with soft-constraints parameterized by the predictions. Recently, predict-and-optimize (PnO) was proposed for end-to-end training of prediction models by back-propagating the cost of decisions through the optimization problem. But, PnO is unable to scale to the large prediction horizons prevalent in cloud computing. To tackle this issue, we propose the Predict-and-Critic (PnC) framework that outperforms PnO with just a two-step horizon by leveraging reinforcement learning. PnC jointly trains a prediction model and a terminal Q function that approximates cost-to-go over a long horizon, by back-propagating the cost of decisions through the optimization problem \emph{and from the future}. The terminal Q function allows us to solve a much smaller two-step horizon optimization problem than the multi-step horizon necessary in PnO. We evaluate PnO and the PnC framework on two datasets, three workloads, and with disturbances not modeled in the optimization problem. We find that PnC significantly improves decision quality over PnO, even when the optimization problem is not a perfect representation of reality. We also find that hardening the soft constraints of the MILP and back-propagating through the constraints improves decision quality for both PnO and PnC.