Can Gaze Inform Egocentric Action Recognition?

PubDate: Jun 2022
Teams: Indiana University Bloomington;Meta
Writers: Zehua Zhang, David Crandall, Michael J. Proulx, Sachin S. Talathi, Abhishek Sharma
PDF: Can Gaze Inform Egocentric Action Recognition?
Abstract
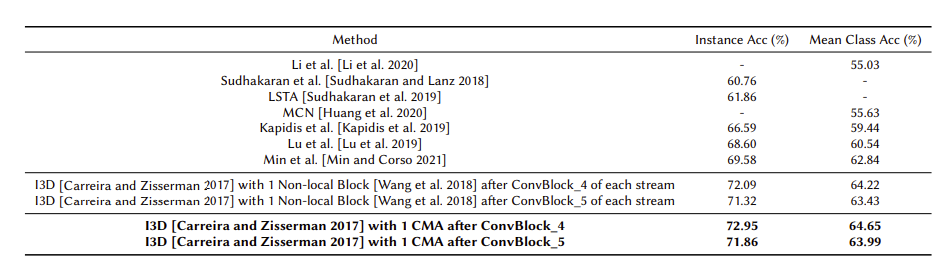
We investigate the hypothesis that gaze-signal can improve egocentric action recognition on the standard benchmark, EGTEA Gaze++ dataset. In contrast to prior work where gaze-signal was only used during training, we formulate a novel neural fusion approach, Cross-modality Attention Blocks (CMA), to leverage gaze-signal for action recognition during inference as well. CMA combines information from different modalities at different levels of abstraction to achieve state-of-the-art performance for egocentric action recognition. Specifically, fusing the video-stream with optical-flow with CMA outperforms the current state-of-the-art by 3%. However, when CMA is employed to fuse gaze-signal with video-stream data, no improvements are observed. Further investigation of this counter-intuitive finding indicates that small spatial overlap between the network’s attention-map and gaze ground-truth renders the gaze-signal uninformative for this benchmark. Based on our empirical findings, we recommend improvements to the current benchmark to develop practical systems for egocentric video understanding with gaze-signal.