adaPARL: Adaptive Privacy-Aware Reinforcement Learning for Sequential-Decision Making Human-in-the-Loop Systems

PubDate: Mar 2023
Teams: University of California Irvine
Writers: Mojtaba Taherisadr, Stelios Andrew Stavroulakis, Salma Elmalaki
Abstract
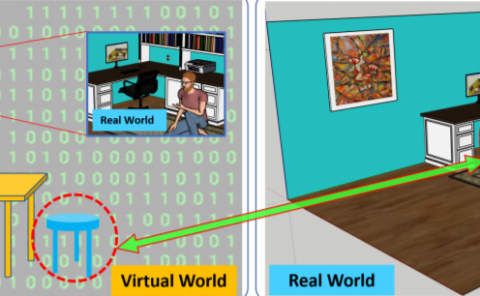
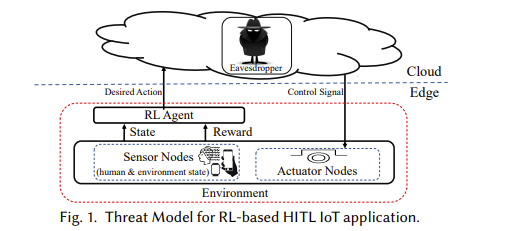
Reinforcement learning (RL) presents numerous benefits compared to rule-based approaches in various applications. Privacy concerns have grown with the widespread use of RL trained with privacy-sensitive data in IoT devices, especially for human-in-the-loop systems. On the one hand, RL methods enhance the user experience by trying to adapt to the highly dynamic nature of humans. On the other hand, trained policies can leak the user’s private information. Recent attention has been drawn to designing privacy-aware RL algorithms while maintaining an acceptable system utility. A central challenge in designing privacy-aware RL, especially for human-in-the-loop systems, is that humans have intrinsic variability and their preferences and behavior evolve. The effect of one privacy leak mitigation can be different for the same human or across different humans over time. Hence, we can not design one fixed model for privacy-aware RL that fits all. To that end, we propose adaPARL, an adaptive approach for privacy-aware RL, especially for human-in-the-loop IoT systems. adaPARL provides a personalized privacy-utility trade-off depending on human behavior and preference. We validate the proposed adaPARL on two IoT applications, namely (i) Human-in-the-Loop Smart Home and (ii) Human-in-the-Loop Virtual Reality (VR) Smart Classroom. Results obtained on these two applications validate the generality of adaPARL and its ability to provide a personalized privacy-utility trade-off. On average, for the first application, adaPARL improves the utility by 57% over the baseline and by 43% over randomization. adaPARL also reduces the privacy leak by 23% on average. For the second application, adaPARL decreases the privacy leak to 44% before the utility drops by 15%.