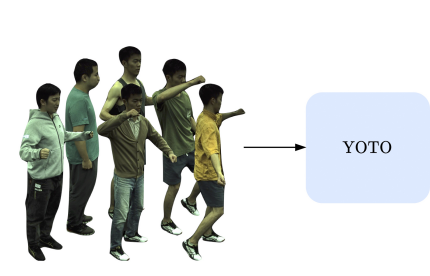
You Only Train Once: Multi-Identity Free-Viewpoint Neural Human Rendering from Monocular Videos

PubDate: Mar 2023
Teams: The Hong Kong University of Science and Technology;Clova AI
Writers: Jaehyeok Kim, Dongyoon Wee, Dan Xu
PDF: You Only Train Once: Multi-Identity Free-Viewpoint Neural Human Rendering from Monocular Videos
Abstract
We introduce You Only Train Once (YOTO), a dynamic human generation framework, which performs free-viewpoint rendering of different human identities with distinct motions, via only one-time training from monocular videos. Most prior works for the task require individualized optimization for each input video that contains a distinct human identity, leading to a significant amount of time and resources for the deployment, thereby impeding the scalability and the overall application potential of the system. In this paper, we tackle this problem by proposing a set of learnable identity codes to expand the capability of the framework for multi-identity free-viewpoint rendering, and an effective pose-conditioned code query mechanism to finely model the pose-dependent non-rigid motions. YOTO optimizes neural radiance fields (NeRF) by utilizing designed identity codes to condition the model for learning various canonical T-pose appearances in a single shared volumetric representation. Besides, our joint learning of multiple identities within a unified model incidentally enables flexible motion transfer in high-quality photo-realistic renderings for all learned appearances. This capability expands its potential use in important applications, including Virtual Reality. We present extensive experimental results on ZJU-MoCap and PeopleSnapshot to clearly demonstrate the effectiveness of our proposed model. YOTO shows state-of-the-art performance on all evaluation metrics while showing significant benefits in training and inference efficiency as well as rendering quality. The code and model will be made publicly available soon.