Cross-Modal Retrieval for Motion and Text via MildTriple Loss

PubDate: May 2023
Teams: Chongqing University of Technology;Peking University
Writers: Sheng Yan, Haoqiang Wang, Xin Du, Mengyuan Liu, Hong Liu
PDF: Cross-Modal Retrieval for Motion and Text via MildTriple Loss
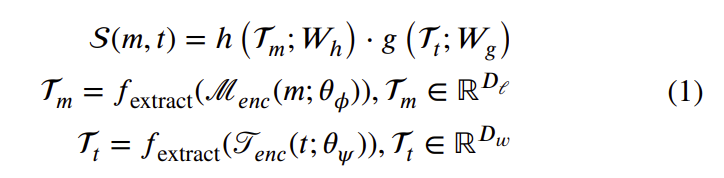
Abstract
Cross-modal retrieval has become a prominent research topic in computer vision and natural language processing with advances made in image-text and video-text retrieval technologies. However, cross-modal retrieval between human motion sequences and text has not garnered sufficient attention despite the extensive application value it holds, such as aiding virtual reality applications in better understanding users’ actions and language. This task presents several challenges, including joint modeling of the two modalities, demanding the understanding of person-centered information from text, and learning behavior features from 3D human motion sequences. Previous work on motion data modeling mainly relied on autoregressive feature extractors that may forget previous information, while we propose an innovative model that includes simple yet powerful transformer-based motion and text encoders, which can learn representations from the two different modalities and capture long-term dependencies. Furthermore, the overlap of the same atomic actions of different human motions can cause semantic conflicts, leading us to explore a new triplet loss function, MildTriple Loss. it leverages the similarity between samples in intra-modal space to guide soft-hard negative sample mining in the joint embedding space to train the triplet loss and reduce the violation caused by false negative samples. We evaluated our model and method on the latest HumanML3D and KIT Motion-Language datasets, achieving a 62.9\% recall for motion retrieval and a 71.5\% recall for text retrieval (based on R@10) on the HumanML3D dataset. Our code is available at this https URL.
