Cicero: Addressing Algorithmic and Architectural Bottlenecks in Neural Rendering by Radiance Warping and Memory Optimizations

PubDate: Apr 2024
Teams: Shanghai Jiao Tong University;University of Rochester
Writers: Yu Feng, Zihan Liu, Jingwen Leng, Minyi Guo, Yuhao Zhu
Abstract
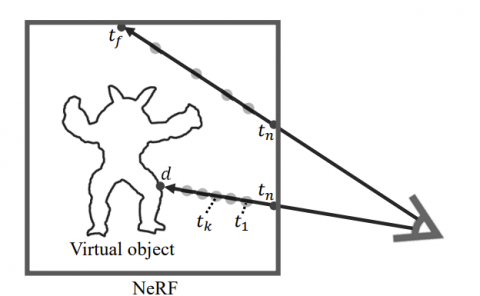
Neural Radiance Field (NeRF) is widely seen as an alternative to traditional physically-based rendering. However, NeRF has not yet seen its adoption in resource-limited mobile systems such as Virtual and Augmented Reality (VR/AR), because it is simply extremely slow. On a mobile Volta GPU, even the state-of-the-art NeRF models generally execute only at 0.8 FPS. We show that the main performance bottlenecks are both algorithmic and architectural. We introduce, CICERO, to tame both forms of inefficiencies. We first introduce two algorithms, one fundamentally reduces the amount of work any NeRF model has to execute, and the other eliminates irregular DRAM accesses. We then describe an on-chip data layout strategy that eliminates SRAM bank conflicts. A pure software implementation of CICERO offers an 8.0x speed-up and 7.9x energy saving over a mobile Volta GPU. When compared to a baseline with a dedicated DNN accelerator, our speed-up and energy reduction increase to 28.2x and 37.8x, respectively - all with minimal quality loss (less than 1.0 dB peak signal-to-noise ratio reduction).