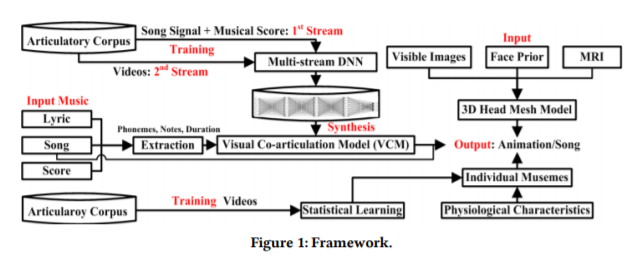
3D Singing Head for Music VR: Learning External and Internal Articulatory Synchronicity from Lyric, Audio and Notes

PubDate: October 2019
Teams: University of Science and Technology of China;The State University of New York at Buffalo
Writers: Jun Yu;Chang Wen Chen;Zengfu Wang
Abstract
We propose a real-time 3D singing head system to enhance the talking head on model integrity, keyframe generation and song synchronicity. The individual head appearance meshes are first obtained by matching multi-view visible images with face prior for accuracy, and then used to reconstruct entire head model by integrating with generic internal articulatory meshes for efficiency. After embedding physiology, the keyframes of each phoneme-music note correspondence are substantially synthesized from real articulation data. The song synchronicity of articulators is learned using a deep neural network to train visual co-articulation model (VCM) on parallel audio-visual data. Finally, the keyframes of adjacent phoneme-music note correspondences are blended by VCM to produce song synchronized animation. Compared to state-of-the-art baselines, our system can not only clearly distinguish phonemes and notes, but also significantly reduce the dependence on training data.