Self-Supervised Adaptation of High-Fidelity Face Models for Monocular Performance Tracking

Title: Self-Supervised Adaptation of High-Fidelity Face Models for Monocular Performance Tracking
Teams: Facebook
Writers: Jae Shin Yoon, Takaaki Shiratori, Shoou-I Yu, Hyun Soo Park
Publication date: June 16, 2019
Abstract
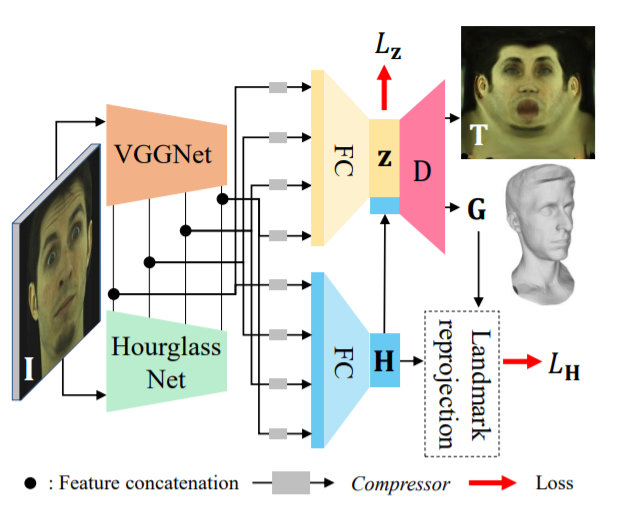
Improvements in data-capture and face modeling techniques have enabled us to create high-fidelity realistic face models. However, driving these realistic face models requires special input data, e.g. 3D meshes and unwrapped textures. Also, these face models expect clean input data taken under controlled lab environments, which is very different from data collected in the wild. All these constraints make it challenging to use the high-fidelity models in tracking for commodity cameras. In this paper, we propose a self-supervised domain adaptation approach to enable the animation of high-fidelity face models from a commodity camera. Our approach first circumvents the requirement for special input data by training a new network that can directly drive a face model just from a single 2D image. Then, we overcome the domain mismatch between lab and uncontrolled environments by performing self-supervised domain adaptation based on “consecutive frame texture consistency” based on the assumption that the appearance of the face is consistent over consecutive frames, avoiding the necessity of modeling the new environment such as lighting or background. Experiments show that we are able to drive a high-fidelity face model to perform complex facial motion from a cellphone camera without requiring any labeled data from the new domain.