ImVoteNet: Boosting 3D object detection in point clouds with image votes

PubDate: 29 Jan 2020
Teams: Facebook, 2Stanford University
Writers: Charles R. Qi, Xinlei Chen, Or Litany, Leonidas J. Guibas
PDF: ImVoteNet: Boosting 3D object detection in point clouds with image votes
Abstract
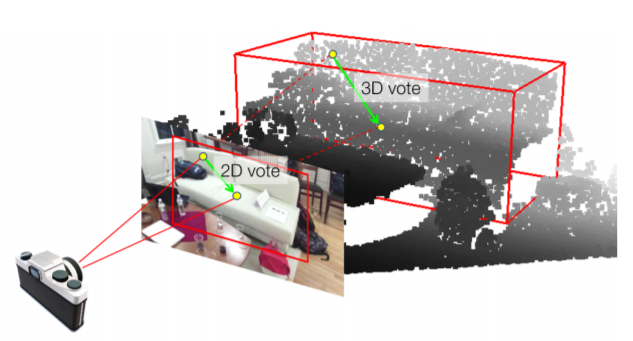
3D object detection has seen quick progress thanks to advances in deep learning on point clouds. A few recent works have even shown state-of-the-art performance with just point clouds input (e.g. VoteNet). However, point cloud data have inherent limitations. They are sparse, lack color information and often suffer from sensor noise. Images, on the other hand, have high resolution and rich texture. Thus they can complement the 3D geometry provided by point clouds. Yet how to effectively use image information to assist point cloud based detection is still an open question. In this work, we build on top of VoteNet and propose a 3D detection architecture called ImVoteNet specialized for RGB-D scenes. ImVoteNet is based on fusing 2D votes in images and 3D votes in point clouds. Compared to prior work on multi-modal detection, we explicitly extract both geometric and semantic features from the 2D images. We leverage camera parameters to lift these features to 3D. To improve the synergy of 2D-3D feature fusion, we also propose a multi-tower training scheme. We validate our model on the challenging SUN RGB-D dataset, advancing state-of-the-art results by 5.7 mAP. We also provide rich ablation studies to analyze the contribution of each design choice.