SeCoST: Sequential Co-Supervision for Weakly Labeled Audio Event Detection

Title: SeCoST: Sequential Co-Supervision for Weakly Labeled Audio Event Detection
Teams: Facebook
Writers: Anurag Kumar, Vamsi Krishna Ithapu
Publication date: May 4, 2020
Abstract
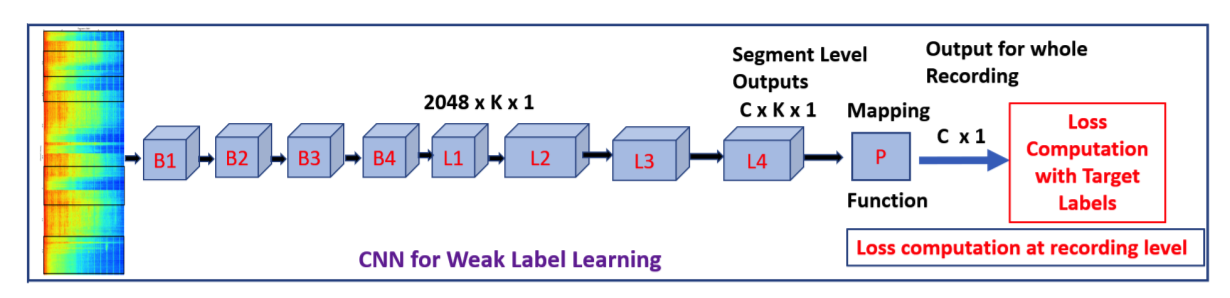
Weakly supervised learning algorithms are critical for scaling audio event detection to several hundreds of sound categories. Such learning models should not only disambiguate sound events efficiently with minimal class-specific annotation but also be robust to label noise, which is more apparent with weak labels instead of strong annotations. In this work, we propose a new framework for designing learning models with weak supervision by bridging ideas from sequential learning and knowledge distillation. We refer to the proposed methodology as SeCoST (pronounced Sequest) — Sequential Co-supervision for training generations of Students. SeCoST incrementally builds a cascade of student-teacher pairs via a novel knowledge transfer method. Our evaluations on Audioset (the largest weakly labeled dataset available) show that SeCoST achieves a mean average precision of 0.383 while outperforming prior state of the art by a considerable margin.