Learning 6-DOF Grasping Interaction via Deep Geometry-aware 3D Representations

PubDate: Jun 2018
Teams: University of Michigan;Google;X Inc
Writers: Xinchen Yan, Jasmine Hsu, Mohi Khansari, Yunfei Bai, Arkanath Pathak, Abhinav Gupta, James Davidson, Honglak Lee
PDF: Learning 6-DOF Grasping Interaction via Deep Geometry-aware 3D Representations
Abstract
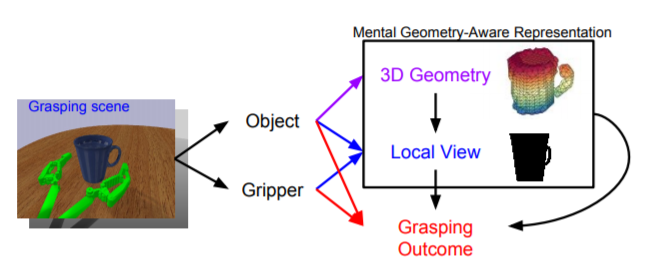
This paper focuses on the problem of learning 6-DOF grasping with a parallel jaw gripper in simulation. We propose the notion of a geometry-aware representation in grasping based on the assumption that knowledge of 3D geometry is at the heart of interaction. Our key idea is constraining and regularizing grasping interaction learning through 3D geometry prediction. Specifically, we formulate the learning of deep geometry-aware grasping model in two steps: First, we learn to build mental geometry-aware representation by reconstructing the scene (i.e., 3D occupancy grid) from RGBD input via generative 3D shape modeling. Second, we learn to predict grasping outcome with its internal geometry-aware representation. The learned outcome prediction model is used to sequentially propose grasping solutions via analysis-by-synthesis optimization. Our contributions are fourfold: (1) To best of our knowledge, we are presenting for the first time a method to learn a 6-DOF grasping net from RGBD input; (2) We build a grasping dataset from demonstrations in virtual reality with rich sensory and interaction annotations. This dataset includes 101 everyday objects spread across 7 categories, additionally, we propose a data augmentation strategy for effective learning; (3) We demonstrate that the learned geometry-aware representation leads to about 10 percent relative performance improvement over the baseline CNN on grasping objects from our dataset. (4) We further demonstrate that the model generalizes to novel viewpoints and object instances.