LookinGood: Enhancing Performance Capture with Real-time Neural Re-Rendering

PubDate: Nov 2018
Teams: Google Inc
Writers: Ricardo Martin-Brualla, Rohit Pandey, Shuoran Yang, Pavel Pidlypenskyi, Jonathan Taylor, Julien Valentin, Sameh Khamis, Philip Davidson, Anastasia Tkach, Peter Lincoln, Adarsh Kowdle, Christoph Rhemann, Dan B Goldman, Cem Keskin, Steve Seitz, Shahram Izadi, Sean Fanello
PDF: LookinGood: Enhancing Performance Capture with Real-time Neural Re-Rendering
Project: LookinGood: Enhancing Performance Capture with Real-time Neural Re-Rendering
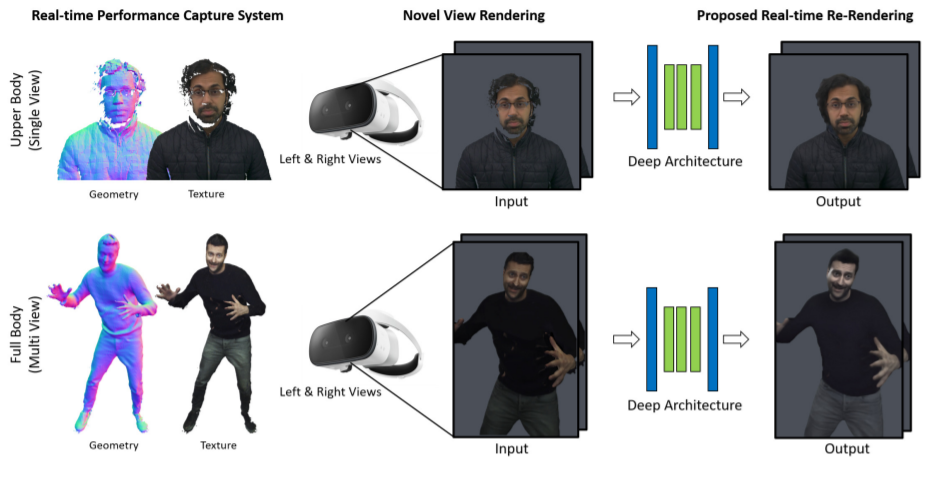
Abstract
Motivated by augmented and virtual reality applications such as telepresence, there has been a recent focus in real-time performance capture of humans under motion. However, given the real-time constraint, these systems often suffer from artifacts in geometry and texture such as holes and noise in the final rendering, poor lighting, and low-resolution textures. We take the novel approach to augment such real-time performance capture systems with a deep architecture that takes a rendering from an arbitrary viewpoint, and jointly performs completion, super resolution, and denoising of the imagery in real-time. We call this approach neural (re-)rendering, and our live system “LookinGood”. Our deep architecture is trained to produce high resolution and high quality images from a coarse rendering in real-time. First, we propose a self-supervised training method that does not require manual ground-truth annotation. We contribute a specialized reconstruction error that uses semantic information to focus on relevant parts of the subject, e.g. the face. We also introduce a salient reweighing scheme of the loss function that is able to discard outliers. We specifically design the system for virtual and augmented reality headsets where the consistency between the left and right eye plays a crucial role in the final user experience. Finally, we generate temporally stable results by explicitly minimizing the difference between two consecutive frames. We tested the proposed system in two different scenarios: one involving a single RGB-D sensor, and upper body reconstruction of an actor, the second consisting of full body 360 degree capture. Through extensive experimentation, we demonstrate how our system generalizes across unseen sequences and subjects.
