Learning multimodal representations for sample-efficient recognition of human actions

PubDate: Mar 2019
Teams: University of Lisbon;SOKENDAI (The Graduate University for
Advanced Studies)
Writers: Miguel Vasco, Francisco S. Melo, David Martins de Matos, Ana Paiva, Tetsunari Inamura
PDF: Learning multimodal representations for sample-efficient recognition of human actions
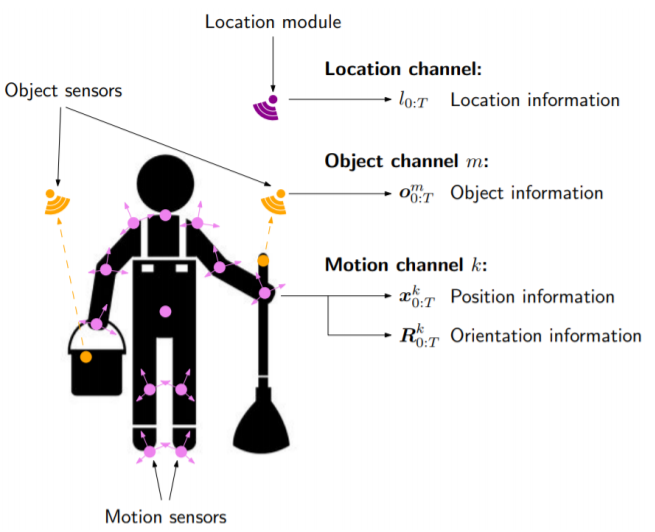
Abstract
Humans interact in rich and diverse ways with the environment. However, the representation of such behavior by artificial agents is often limited. In this work we present \textit{motion concepts}, a novel multimodal representation of human actions in a household environment. A motion concept encompasses a probabilistic description of the kinematics of the action along with its contextual background, namely the location and the objects held during the performance. Furthermore, we present Online Motion Concept Learning (OMCL), a new algorithm which learns novel motion concepts from action demonstrations and recognizes previously learned motion concepts. The algorithm is evaluated on a virtual-reality household environment with the presence of a human avatar. OMCL outperforms standard motion recognition algorithms on an one-shot recognition task, attesting to its potential for sample-efficient recognition of human actions.

