HERALD: Optimizing Heterogeneous DNN Accelerators for Edge Devices

PubDate: Jun 2020
Teams: Georgia Institute of Technology;Facebook
Writers: Hyoukjun Kwon, Liangzhen Lai, Tushar Krishna, Vikas Chandra
PDF: HERALD: Optimizing Heterogeneous DNN Accelerators for Edge Devices
Abstract
New real time applications such as virtual reality (VR) with multiple sub-tasks (e.g., image segmentation, hand tracking, etc.) based on deep neural networks (DNNs) are emerging. Such applications rely on multiple DNNs for each sub-task with heterogeneity and require to meet target processing rates for each sub-task. Thus, the new compound DNN workload imposes new challenges to accelerator designs in two folds: (1) meeting target processing rate for each DNN for sub-tasks and (2) efficiently processing heterogeneous layers. As a solution, we explore heterogeneous DNN accelerators (HDAs). HDAs consist of multiple accelerator substrates (i.e., sub-accelerators) to support model parallelism that implements different mapping styles to provide adaptivity to heterogeneous DNN layers. However, HDA’s performance and energy heavily depend on (1) how we partition hardware resources for sub-accelerators, and (2) how we schedule layers on the sub-accelerators.
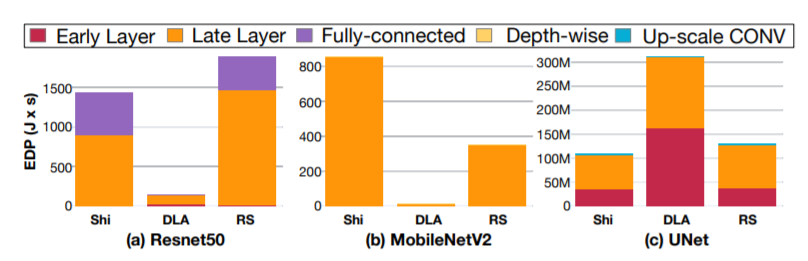
Therefore, we propose an HDA optimization framework, Herald, which performs co-optimization of hardware partitioning and layer schedluing. Herald exploits the simplicity of dependence graph of DNN layers to reduce the complexity of the problem, which on average requires 9.48 ms per layer on a laptop with i9-9880H processor and 16GB memory. Herald can be utilized both in design time to perform co-optimization (optimizer) and in compile time to perform layer scheduling and report expected latency and energy (cost model/scheduler). In our case studies, co-optimized HDAs with the best EDP Herald identified provided 56.0% EDP improvements with 46.82% latency and 6.3% energy benefits on average across workloads and accelerators we evaluate compared to the best monolithic accelerators for each evaluation setting by deploying two complementary-style sub-accelerators in an HDA.