SoundSpaces: Audio-Visual Navigation in 3D Environments

PubDate: August 23, 2020
Teams: UT Austin, UIUC, Facebook Reality Labs, Facebook AI Research
Writers: Changan Chen, Unnat Jain, Carl Schissler, Sebastià V. Amengual Garí, Ziad Al-Halah, Vamsi Krishna Ithapu, Philip Robinson, Kristen Grauman
PDF: SoundSpaces: Audio-Visual Navigation in 3D Environments
Abstract
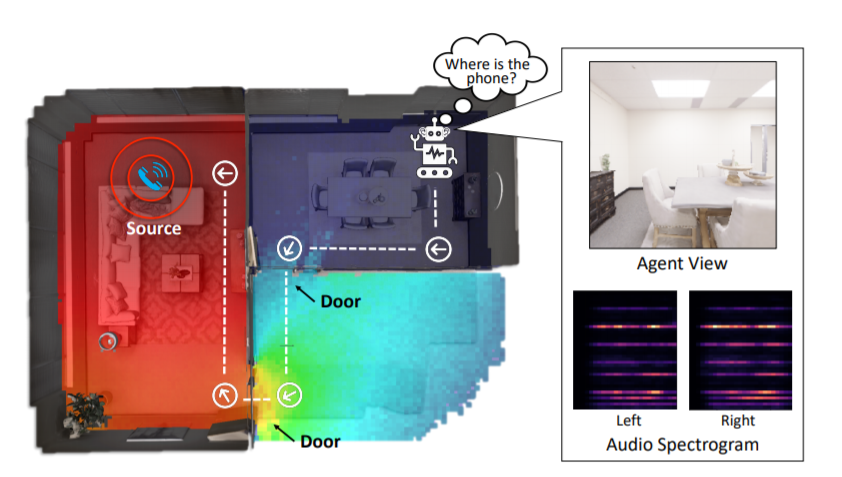
Moving around in the world is naturally a multisensory experience, but today’s embodied agents are deaf—restricted to solely their visual perception of the environment. We introduce audio-visual navigation for complex, acoustically and visually realistic 3D environments. By both seeing and hearing, the agent must learn to navigate to a sounding object. We propose a multi-modal deep reinforcement learning approach to train navigation policies end-to-end from a stream of egocentric audio-visual observations, allowing the agent to (1) discover elements of the geometry of the physical space indicated by the reverberating audio and (2) detect and follow sound-emitting targets. We further introduce SoundSpaces: a first-of-its-kind dataset of audio renderings based on geometrical acoustic simulations for two sets of publicly available 3D environments (Matterport3D and Replica), and we instrument Habitat to support the new sensor, making it possible to insert arbitrary sound sources in an array of real-world scanned environments. Our results show that audio greatly benefits embodied visual navigation in 3D spaces, and our work lays groundwork for new research in embodied AI with audio-visual perception. Project: http://vision.cs.utexas.edu/projects/audio_visual_navigation.
