Teacher-Student Training and Triplet Loss for Facial Expression Recognition under Occlusion

PubDate: Aug 2020
Teams: Novustech Services;University of Bucharest
Writers: Mariana-Iuliana Georgescu, Radu Tudor Ionescu
PDF: Teacher-Student Training and Triplet Loss for Facial Expression Recognition under Occlusion
Abstract
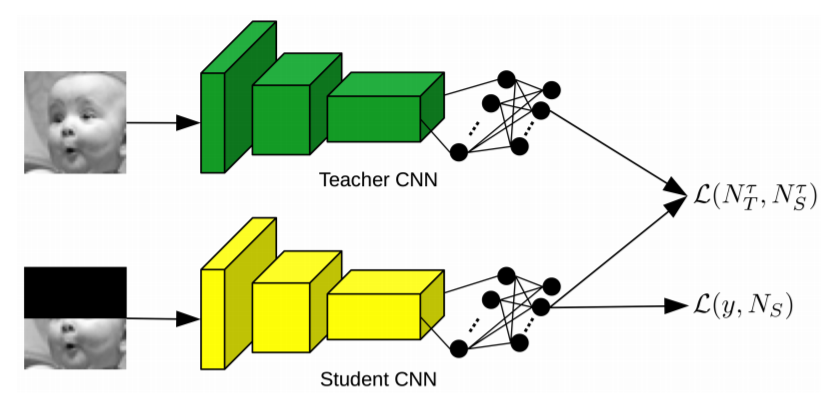
In this paper, we study the task of facial expression recognition under strong occlusion. We are particularly interested in cases where 50% of the face is occluded, e.g. when the subject wears a Virtual Reality (VR) headset. While previous studies show that pre-training convolutional neural networks (CNNs) on fully-visible (non-occluded) faces improves the accuracy, we propose to employ knowledge distillation to achieve further improvements. First of all, we employ the classic teacher-student training strategy, in which the teacher is a CNN trained on fully-visible faces and the student is a CNN trained on occluded faces. Second of all, we propose a new approach for knowledge distillation based on triplet loss. During training, the goal is to reduce the distance between an anchor embedding, produced by a student CNN that takes occluded faces as input, and a positive embedding (from the same class as the anchor), produced by a teacher CNN trained on fully-visible faces, so that it becomes smaller than the distance between the anchor and a negative embedding (from a different class than the anchor), produced by the student CNN. Third of all, we propose to combine the distilled embeddings obtained through the classic teacher-student strategy and our novel teacher-student strategy based on triplet loss into a single embedding vector. We conduct experiments on two benchmarks, FER+ and AffectNet, with two CNN architectures, VGG-f and VGG-face, showing that knowledge distillation can bring significant improvements over the state-of-the-art methods designed for occluded faces in the VR setting.