Large Scale Audiovisual Learning of Sounds with Weakly Labeled Data

PubDate: July 11, 2020
Teams: Facebook Reality Labs
Writers: Haytham M. Fayek, Anurag Kumar
PDF: Large Scale Audiovisual Learning of Sounds with Weakly Labeled Data
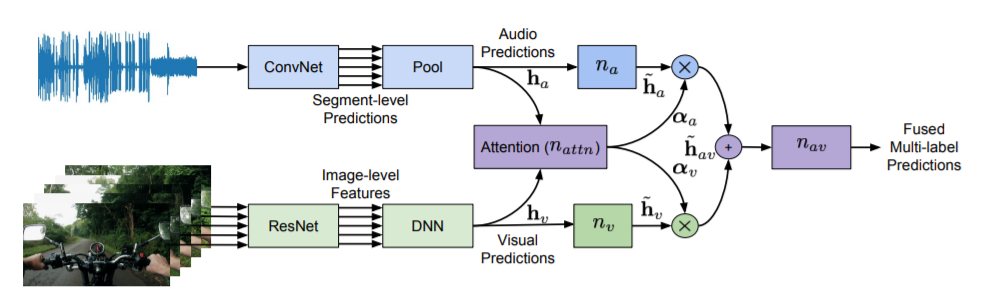
Abstract
Recognizing sounds is a key aspect of computational audio scene analysis and machine perception. In this paper, we advocate that sound recognition is inherently a multi-modal audiovisual task in that it is easier to differentiate sounds using both the audio and visual modalities as opposed to one or the other. We present an audiovisual fusion model that learns to recognize sounds from weakly labeled video recordings. The proposed fusion model utilizes an attention mechanism to dynamically combine the outputs of the individual audio and visual models. Experiments on the large scale sound events dataset, AudioSet, demonstrate the efficacy of the proposed model, which outperforms the single-modal models, and state-of-the-art fusion and multi-modal models. We achieve a mean Average Precision (mAP) of 46.16 on Audioset, outperforming prior state of the art by approximately +4.35 mAP (relative: 10.4%).
