SqueezeSegV3: Spatially-Adaptive Convolution for Efficient Point-Cloud Segmentation

PubDate: August 2020
Teams: University of California;Facebook
Writers: Chenfeng Xu, Bichen Wu, Zining Wang, Wei Zhan, Peter Vajda, Kurt Keutzer, Masayoshi Tomizuka
PDF: SqueezeSegV3: Spatially-Adaptive Convolution for Efficient Point-Cloud Segmentation
Abstract
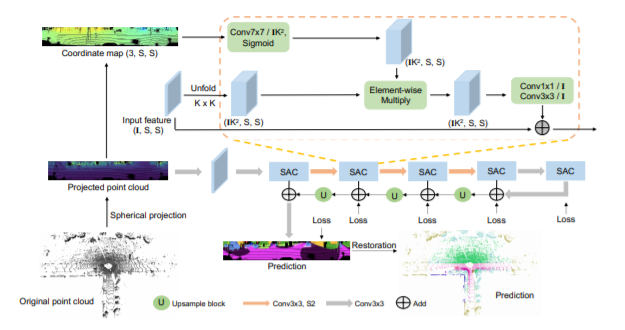
LiDAR point-cloud segmentation is an important problem for many applications. For large-scale point cloud segmentation, the de facto method is to project a 3D point cloud to get a 2D LiDAR image and use convolutions to process it. Despite the similarity between regular RGB and LiDAR images, we are the first to discover that the feature distribution of LiDAR images changes drastically at different image locations. Using standard convolutions to process such LiDAR images is problematic, as convolution filters pick up local features that are only active in specific regions in the image. As a result, the capacity of the network is under-utilized and the segmentation performance decreases. To fix this, we propose Spatially-Adaptive Convolution (SAC) to adopt different filters for different locations according to the input image. SAC can be computed efficiently since it can be implemented as a series of element-wise multiplications, im2col, and standard convolution. It is a general framework such that several previous methods can be seen as special cases of SAC. Using SAC, we build SqueezeSegV3 for LiDAR point-cloud segmentation and outperform all previous published methods by at least 2.0% mIoU on the SemanticKITTI benchmark. Code and pretrained model are available at https://github.com/chenfengxu714/SqueezeSegV3.