3D Shape Reconstruction from Vision and Touch

PubDate: Dec, 2020
Teams: Facebook AI Research, McGill University, University of California, Berkeley
Writers: Edward J. Smith, Roberto Calandra, Adriana Romero, Georgia Gkioxari, David Meger, Jitendra Malik, Michal Drozdzal
PDF: 3D Shape Reconstruction from Vision and Touch
Project: 3D-Vision-and-Touch
Abstract
If we want to build AI systems that can interact in and learn from the world around us, touch can be as equally important as sight and speech. If you’re asked about the shape of an object at hand, for instance, you’d typically pick it up and examine it with your hand and eyes at the same time. For AI agents, combining vision and touch could lead to a richer understanding of objects in 3D. But this research area has been underexplored in AI.
We’re introducing a new method to accelerate progress in building AI that leverages two senses together. We simultaneously fuse the strengths of sight and touch to perform 3D shape reconstruction. We did this by creating a new data set that’s made up of simulated interactions between a robotic hand and 3D objects.
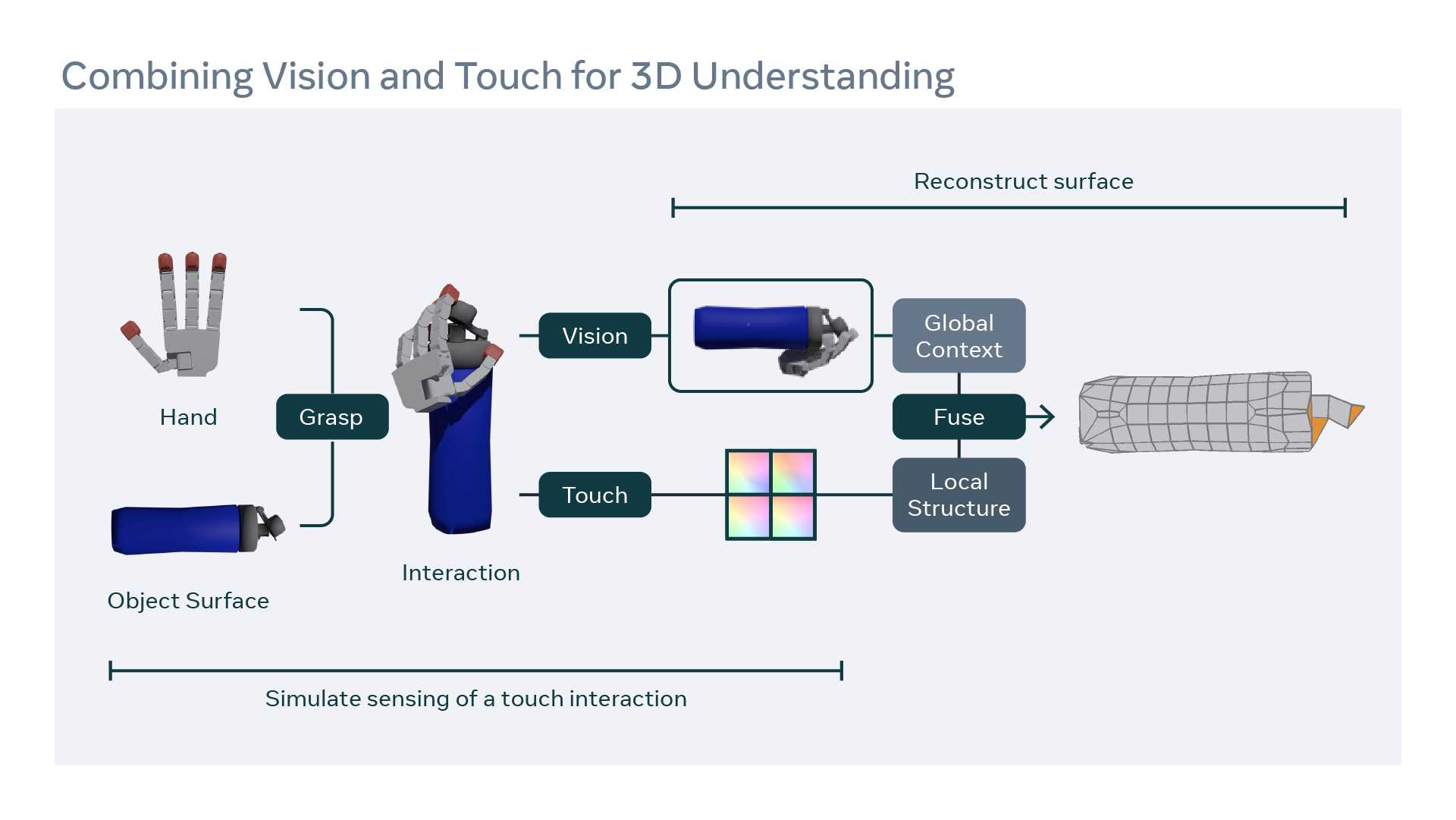
Our approach to 3D shape reconstruction combines a single RGB image with four touch readings. We start by predicting touch charts from touch recordings and projecting the visual signal onto all charts. Then, we feed the charts into an iterative deformation process, where we enforce touch consistency. As a result, we obtain a global prediction of deformed charts.
When a robot hand grasps an object, we receive tactile and pose information of the grasp. We combine this with an image of the object and use a graph convolutional network to predict local charts of information at each touch site. We use the corresponding vision information to predict global charts that close the surface around them in a fill-in-the-blank type of process. This combination of local structure and global context helps us predict 3D shapes with high accuracy.
Our approach outperforms single modality baselines — vision or touch — and it’s also better than baseline methods for multimodal 3D understanding. We also found that the quality of our 3D reconstruction increases with each additional grasp and relevant touch information

