Meta-Reinforcement Learning for Reliable Communication in THz/VLC Wireless VR Networks

PubDate: Jan 2021
Teams: Beijing University of Posts and Telecommunications;Princeton University; Kings College London;Chinese University of Hong Kong
Writers: Yining Wang, Mingzhe Chen, Zhaohui Yang, Walid Saad, Tao luo, Shuguang Cui, H. Vincent Poor
PDF: Meta-Reinforcement Learning for Reliable Communication in THz/VLC Wireless VR Networks
Abstract
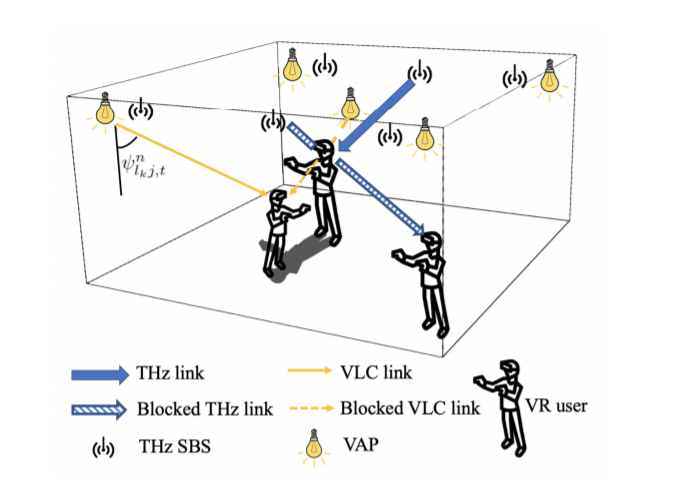
In this paper, the problem of enhancing the quality of virtual reality (VR) services is studied for an indoor terahertz (THz)/visible light communication (VLC) wireless network. In the studied model, small base stations (SBSs) transmit high-quality VR images to VR users over THz bands and light-emitting diodes (LEDs) provide accurate indoor positioning services for them using VLC. Here, VR users move in real time and their movement patterns change over time according to their applications. Both THz and VLC links can be blocked by the bodies of VR users. To control the energy consumption of the studied THz/VLC wireless VR network, VLC access points (VAPs) must be selectively turned on so as to ensure accurate and extensive positioning for VR users. Based on the user positions, each SBS must generate corresponding VR images and establish THz links without body blockage to transmit the VR content. The problem is formulated as an optimization problem whose goal is to maximize the average number of successfully served VR users by selecting the appropriate VAPs to be turned on and controlling the user association with SBSs. To solve this problem, a meta policy gradient (MPG) algorithm that enables the trained policy to quickly adapt to new user movement patterns is proposed. In order to solve the problem for VR scenarios with a large number of users, a dual method based MPG algorithm (D-MPG) with a low complexity is proposed. Simulation results demonstrate that, compared to a baseline trust region policy optimization algorithm (TRPO), the proposed MPG and D-MPG algorithms yield up to 38.2% and 33.8% improvement in the average number of successfully served users as well as 75% and 87.5% gains in the convergence speed, respectively.