Feature Extraction of Human Motion Video Based on Virtual Reality Technology

PubDate: August 2020
Teams: Heilongjiang University
Writers: Mimi Zhou
PDF: Feature Extraction of Human Motion Video Based on Virtual Reality Technology
Abstract
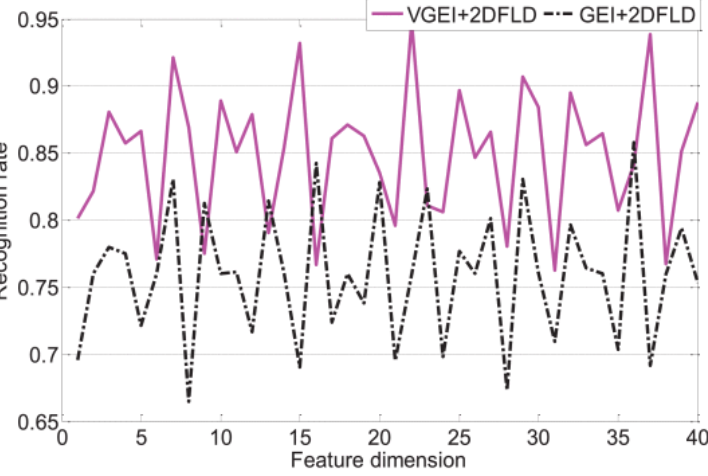
In virtual reality scenes, the premise of moving target recognition in video is accurate target segmentation and extraction of target low-level features. In order to distinguish moving targets, it is not enough to use the underlying features. Further extraction of structural features that reflect the target structure can improve the recognition and tracking of moving targets. In order to ensure the stability of the feature areas extracted from the three-channel most stable extremum region, this article proposes an improved algorithm of the three-channel most stable extremum region to improve the three-channel most stable extremum region. The algorithm can adaptively select the filters of each channel to filter the feature regions extracted from the three most stable extreme value regions. An action cycle is generally 30~50 frames, so it is faster and more advantageous to directly use the first 50 frames of video for processing. In this article, two feature representation methods of variance gait energy graph algorithm and image splitting algorithm are proposed. The variance energy graph algorithm significantly improves the recognition rate; image splitting enhances the robustness of behavior classification. This article proposes a feature representation algorithm of “distance from contour line to center line” to improve the recognition rate. By analyzing the feature extraction methods of principal component analysis, Fisher linear discriminant analysis and maximum divergence difference discriminant analysis, the main component discriminant analysis of row maximum divergence discriminant column and the two-dimensional two-dimensional maximum divergence discriminant analysis of row and column are proposed. This further enhances the ability to classify behaviors.