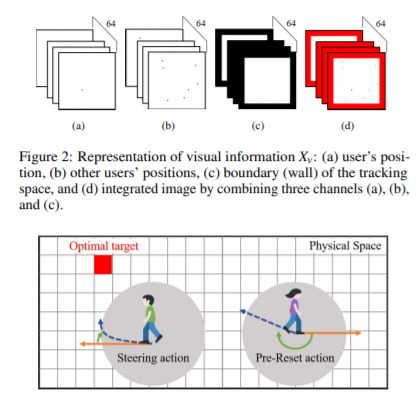
Optimal Planning for Redirected Walking Based on Reinforcement Learning in Multi-user Environment with Irregularly Shaped Physical Space

PubDate: Mar 2020
Teams: Yonsei University
Writers: Dong-Yong Lee*,Yong-Hun Cho†,Dae-Hong Min‡,In-Kwon Lee§
Abstract
Redirected Walking (RDW) enables users to walk in both virtual and physical tracking spaces simultaneously, which is an effective method to increase presence in Virtual Reality (VR). Recently, RDW technologies have been developed in a multi-user environment where multiple users share the same physical tracking space and simultaneously explore the same virtual space. Meanwhile, in the Steer-To-Optimal-Target (S2OT) method, user actions are planned in RDW by introducing machine learning models such as reinforcement learning. In this paper, we propose a new predictive RDW algorithm “Multiuser-Steer-to-Optimal-Target (MS2OT)” that extends the S2OT method into an environment with multiple users and various types of tracking space. In addition to the steering actions used in S2OT, MS2OT considers pre-reset actions and uses more steering targets and an improved reward function. The locations of multiple users and tracking space information are treated as visual information to be the state of the reinforcement learning model in MS2OT. Hence, the artificial neural network of a multilayer threedimensional convolutional neural network with a dueling double deep network architecture is learned through Q-Learning. MS2OT significantly reduces the total number of resets compared to the conventional RDW algorithms such as S2C and APF-RDW in a multi-user environment and improves the total distance and average distance between resets during the same period. Experimental results show that MS2OT can process up to 32 users in real-time