Learning to Refine 3D Human Pose Sequences

Title: Learning to Refine 3D Human Pose Sequences
Teams: Microsoft
Writers: Jieru Mei Xingyu Chen Chunyu Wang Wenjun Zeng
Publication date: September 2019
Abstract
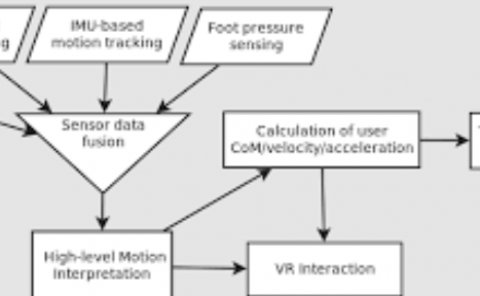
We present a basis approach to refine noisy 3D human pose sequences by jointly projecting them onto a non-linear pose manifold, which is represented by a number of basis dictionaries with each covering a small manifold region. We learn the dictionaries by jointly minimizing the distance between the original poses and their projections on the dictionaries, along with the temporal jittering of the projected poses. During testing, given a sequence of noisy poses which are probably off the manifold, we project them to the manifold using the same strategy as in training for refinement. We apply our approach to the monocular 3D pose estimation and the long term motion prediction tasks. The experimental results on the benchmark dataset shows the estimated 3D poses are notably improved in both tasks. In particular, the smoothness constraint helps generate more robust refinement results even when some poses in the original sequence have large errors.