On the Predictability of HRTFs from Ear Shapes Using Deep Networks

PubDate: June 6, 2021
Teams: Facebook Reality Labs
Writers: Yaxuan Zhou, Hao Jiang, Vamsi Krishna Ithapu
PDF: On the Predictability of HRTFs from Ear Shapes Using Deep Networks
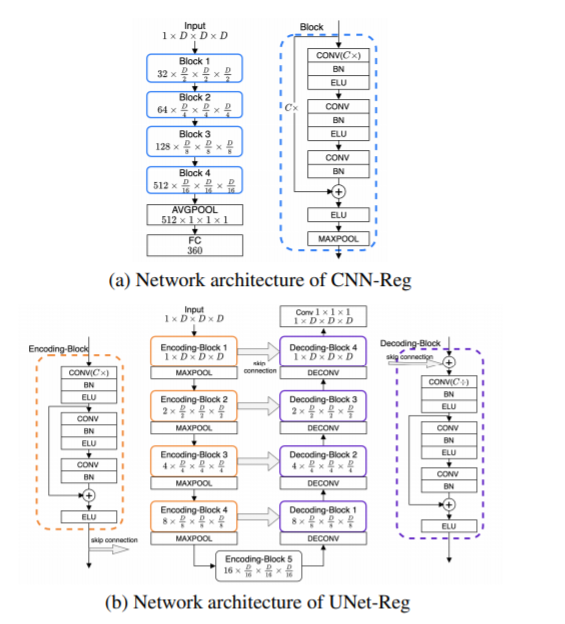
Abstract
Head-Related Transfer Function (HRTF) individualization is critical for immersive and realistic spatial audio rendering in augmented/virtual reality. Neither measurements nor simulations using 3D scans of head/ear are scalable for practical applications. More efficient machine learning approaches are being explored recently, to predict HRTFs from ear images or anthropometric features. However, it is not yet clear whether such models can provide an alternative for direct measurements or high-fidelity simulations. Here, we aim to address this question. Using 3D ear shapes as inputs, we explore the bounds of HRTF predictability using deep neural networks. To that end, we propose and evaluate two models, and identify the lowest achievable spectral distance error when predicting the true HRTF magnitude spectra.