DeepVideoMVS: Multi-View Stereo on Video with Recurrent Spatio-Temporal Fusion

PubDate: Jun 2021
Teams: ETH Zurich;Microsoft Mixed Reality & AI Zurich Lab
Writers: Arda Düzçeker, Silvano Galliani, Christoph Vogel, Pablo Speciale, Mihai Dusmanu, Marc Pollefeys
PDF: DeepVideoMVS: Multi-View Stereo on Video with Recurrent Spatio-Temporal Fusion
Abstract
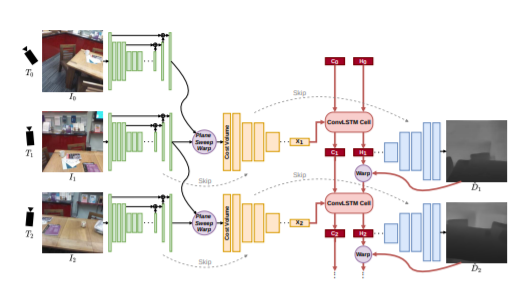
We propose an online multi-view depth prediction approach on posed video streams, where the scene geometry information computed in the previous time steps is propagated to the current time step in an efficient and geometrically plausible way. The backbone of our approach is a real-time capable, lightweight encoder-decoder that relies on cost volumes computed from pairs of images. We extend it by placing a ConvLSTM cell at the bottleneck layer, which compresses an arbitrary amount of past information in its states. The novelty lies in propagating the hidden state of the cell by accounting for the viewpoint changes between time steps. At a given time step, we warp the previous hidden state into the current camera plane using the previous depth prediction. Our extension brings only a small overhead of computation time and memory consumption, while improving the depth predictions significantly. As a result, we outperform the existing state-of-the-art multi-view stereo methods on most of the evaluated metrics in hundreds of indoor scenes while maintaining a real-time performance. Code available: this https URL