To React or not to React: End-to-End Visual Pose Forecasting for Personalized Avatar during Dyadic Conversations

PubDate: December 4, 2019
Teams: Facebook Reality Labs, Carnegie Mellon University
Writers: Chaitanya Ahuja, Shugao Ma, Louis-Philippe Morency, Yaser Sheikh
Abstract
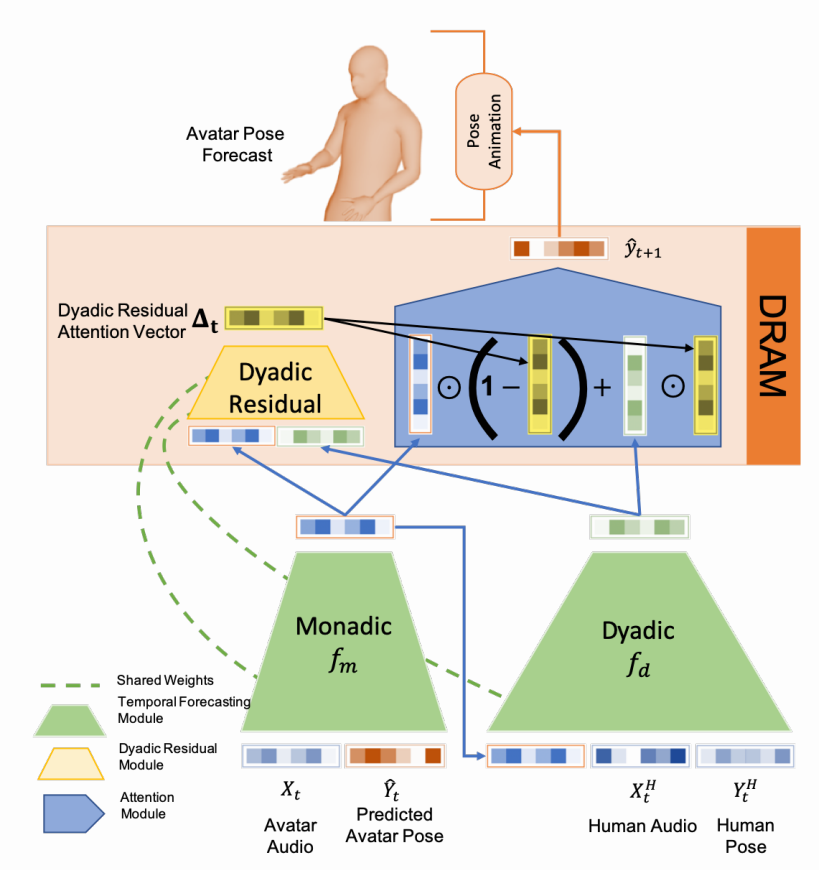
Non verbal behaviours such as gestures, facial expressions, body posture, and para-linguistic cues have been shown to complement or clarify verbal messages. Hence to improve telepresence, in form of an avatar, it is important to model these behaviours, especially in dyadic interactions. Creating such personalized avatars not only requires to model intrapersonal dynamics between a avatar’s speech and their body pose, but it also needs to model interpersonal dynamics with the interlocutor present in the conversation. In this paper, we introduce a neural architecture named Dyadic Residual-Attention Model (DRAM), which integrates intrapersonal (monadic) and interpersonal (dyadic) dynamics using selective attention to generate sequences of body pose conditioned on audio and body pose of the interlocutor and audio of the human operating the avatar. We evaluate our proposed model on dyadic conversational data consisting of pose and audio of both participants, confirming the importance of adaptive attention between monadic and dyadic dynamics when predicting avatar pose. We also conduct a user study to analyze judgments of human observers. Our results confirm that the generated body pose is more natural, models intrapersonal dynamics and interpersonal dynamics better than non-adaptive monadic/dyadic models.