Deep Incremental Learning for Efficient High-Fidelity Face Tracking

Title: Deep Incremental Learning for Efficient High-Fidelity Face Tracking
Teams: Facebook
Writers: Chenglei Wu, Takaaki Shiratori, Yaser Sheikh
Publication date: November 27, 2018
Abstract
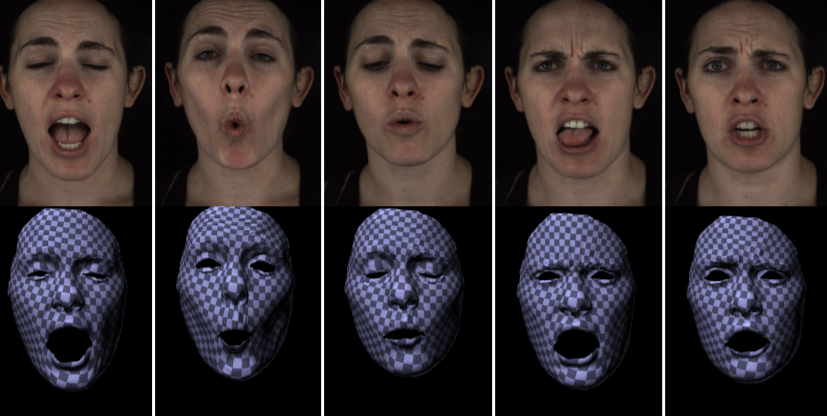
In this paper, we present an incremental learning framework for efficient and accurate facial performance tracking. Our approach is to alternate the modeling step, which takes tracked meshes and texture maps to train our deep learning-based statistical model, and the tracking step, which takes predictions of geometry and texture our model infers from measured images and optimize the predicted geometry by minimizing image, geometry and facial landmark errors. Our Geo-Tex VAE model extends the convolutional variational autoencoder for face tracking, and jointly learns and represents deformations and variations in geometry and texture from tracked meshes and texture maps. To accurately model variations in facial geometry and texture, we introduce the decomposition layer in the Geo-Tex VAE architecture which decomposes the facial deformation into global and local components.
We train the global deformation with a fully-connected network and the local deformations with convolutional layers. Despite running this model on each frame independently – thereby enabling a high amount of parallelization – we validate that our framework achieves sub-millimeter accuracy on synthetic data and outperforms existing methods. We also qualitatively demonstrate high-fidelity, long-duration facial performance tracking on several actors.