Point-Cloud Completion with Pretrained Text-to-image Diffusion Models

PubDate: June 2023
Teams: 1NVIDIA Research;Bar-Ilan University
Writers: Yoni Kasten1 Ohad Rahamim2 Gal Chechik
PDF: Point-Cloud Completion with Pretrained Text-to-image Diffusion Models
Project: Point-Cloud Completion with Pretrained Text-to-image Diffusion Models
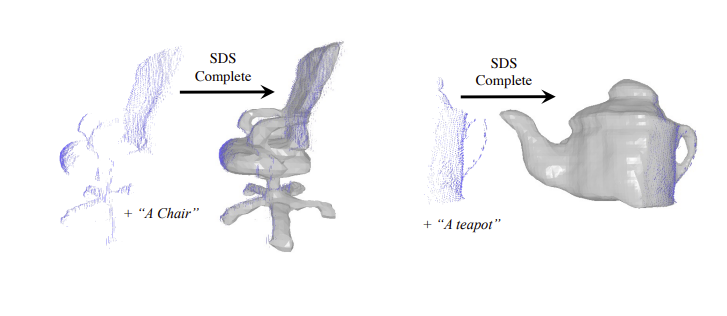
Abstract
Point-cloud data collected in real-world applications are often incomplete, because objects are being observed from specific viewpoints, which only capture one perspective. Data can also be incomplete due to occlusion and low-resolution sampling. Existing approaches to completion rely on training models with datasets of predefined objects to guide the completion of point clouds. Unfortunately, these approaches fail to generalize when tested on objects or real-world setups that are poorly represented in their training set. Here, we leverage recent advances in text-guided 3D shape generation, showing how to use image priors for generating 3D objects. We describe an approach called SDS-Complete that uses a pre-trained text-to-image diffusion model and leverages the text semantics of a given incomplete point cloud of an object, to obtain a complete surface representation. SDS-Complete can complete a variety of objects using test-time optimization without expensive collection of 3D data. We evaluate SDS-Complete on a collection of incomplete scanned objects, captured by real-world depth sensors and LiDAR scanners. We find that it effectively reconstructs objects that are absent from common datasets, reducing Chamfer loss by about 50% on average compared with current methods.