SyncFusion: Multimodal Onset-synchronized Video-to-Audio Foley Synthesis

PubDate: Otc 2023
Teams: Queen Mary University of London;Sapienza University of Rome
Writers: Marco Comunità, Riccardo F. Gramaccioni, Emilian Postolache, Emanuele Rodolà, Danilo Comminiello, Joshua D. Reiss
PDF: SyncFusion: Multimodal Onset-synchronized Video-to-Audio Foley Synthesis
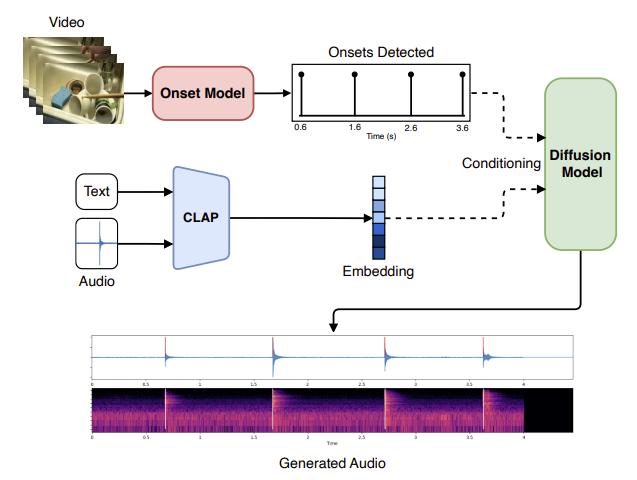
Abstract
Sound design involves creatively selecting, recording, and editing sound effects for various media like cinema, video games, and virtual/augmented reality. One of the most time-consuming steps when designing sound is synchronizing audio with video. In some cases, environmental recordings from video shoots are available, which can aid in the process. However, in video games and animations, no reference audio exists, requiring manual annotation of event timings from the video. We propose a system to extract repetitive actions onsets from a video, which are then used - in conjunction with audio or textual embeddings - to condition a diffusion model trained to generate a new synchronized sound effects audio track. In this way, we leave complete creative control to the sound designer while removing the burden of synchronization with video. Furthermore, editing the onset track or changing the conditioning embedding requires much less effort than editing the audio track itself, simplifying the sonification process. We provide sound examples, source code, and pretrained models to faciliate reproducibility

