Enhancing Robustness in Audio Deepfake Detection for VR Applications using data augmentation and Mixup

PubDate: Otc 2024
Teams:AKCIT Federal University of Goiás
Writers:Gustavo dos Reis Oliveira, Rafaello Virgilli, Lucas Alcântara Souza, Lucas Stefanel Gris, Evellyn Nicole Machado Rosa, Isadora Stéfany Rezende Remigio Mesquita, Daniel Tunnermann, Arlindo Rodrigues Galvão Filho
Abstract
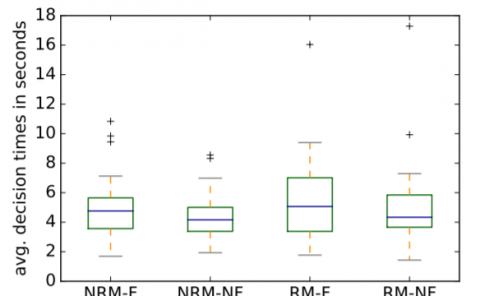
The rapid advancement of virtual reality (VR) technology has heightened the need for robust and reliable deepfake audio detection to ensure the authenticity and integrity of virtual interactions. Although current state-of-the-art models exhibit promising results, they are often overconfident, which can lead to poor generalization and reduced effectiveness against novel or slightly altered deepfake attacks. In this work, we investigate the application of data augmentation techniques and Mixup techniques to increase the diversity of training data and improve the generalization of deepfake audio detection models. Mixup creates new training examples by combining pairs of existing examples, promoting smoother and more robust decision boundaries, while data augmentation creates new training examples altering a sample with a given probability. Our results demonstrate that applying such techniques to the Wav2vec 2.0 model significantly improves its generalization ability, leading to more reliable deepfake detection in VR environments.