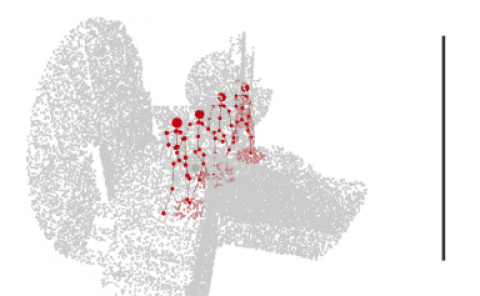
Disentangled Clothed Avatar Generation with Layered Representation

Note: We don't have the ability to review paper
PubDate: Jan 2025
Teams:1Shanghai Jiao Tong University 2The University of Hong Kong
Writers:Weitian Zhang, Sijing Wu, Manwen Liao, Yichao Yan
PDF:Disentangled Clothed Avatar Generation with Layered Representation
Abstract