Note: We don't have the ability to review paper
PubDate: October 2018
Teams: Beihang University
Writers: Chen Li;Mai Xu;Xinzhe Du;Zulin Wang
PDF: Bridge the Gap Between VQA and Human Behavior on Omnidirectional Video: A Large-Scale Dataset and a Deep Learning Model
Abstract
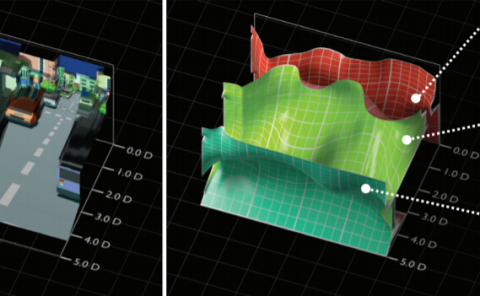
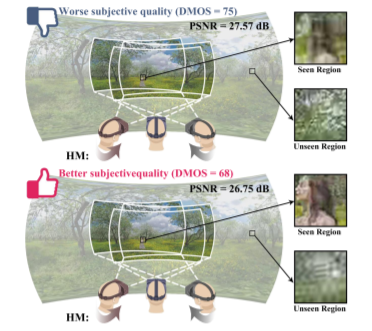
Omnidirectional video enables spherical stimuli with the  viewing range. Meanwhile, only the viewport region of omnidirectional video can be seen by the observer through head movement (HM), and an even smaller region within the viewport can be clearly perceived through eye movement (EM). Thus, the subjective quality of omnidirectional video may be correlated with HM and EM of human behavior. To fill in the gap between subjective quality and human behavior, this paper proposes a large-scale visual quality assessment (VQA) dataset of omnidirectional video, called VQA-OV, which collects 60 reference sequences and 540 impaired sequences. Our VQA-OV dataset provides not only the subjective quality scores of sequences but also the HM and EM data of subjects. By mining our dataset, we find that the subjective quality of omnidirectional video is indeed related to HM and EM. Hence, we develop a deep learning model, which embeds HM and EM, for objective VQA on omnidirectional video. Experimental results show that our model significantly improves the state-of-the-art performance of VQA on omnidirectional video.
viewing range. Meanwhile, only the viewport region of omnidirectional video can be seen by the observer through head movement (HM), and an even smaller region within the viewport can be clearly perceived through eye movement (EM). Thus, the subjective quality of omnidirectional video may be correlated with HM and EM of human behavior. To fill in the gap between subjective quality and human behavior, this paper proposes a large-scale visual quality assessment (VQA) dataset of omnidirectional video, called VQA-OV, which collects 60 reference sequences and 540 impaired sequences. Our VQA-OV dataset provides not only the subjective quality scores of sequences but also the HM and EM data of subjects. By mining our dataset, we find that the subjective quality of omnidirectional video is indeed related to HM and EM. Hence, we develop a deep learning model, which embeds HM and EM, for objective VQA on omnidirectional video. Experimental results show that our model significantly improves the state-of-the-art performance of VQA on omnidirectional video.