A Spatio-temporal Transformer for 3D Human Motion Prediction

PubDate: Jun 2020
Teams: ETH Zurich; Peking University
Writers: Emre Aksan, Peng Cao, Manuel Kaufmann, Otmar Hilliges
PDF: A Spatio-temporal Transformer for 3D Human Motion Prediction
Project: A Spatio-temporal Transformer for 3D Human Motion Prediction
Abstract
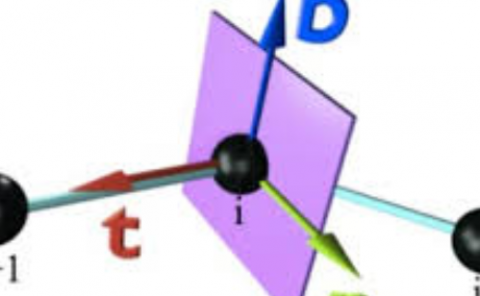
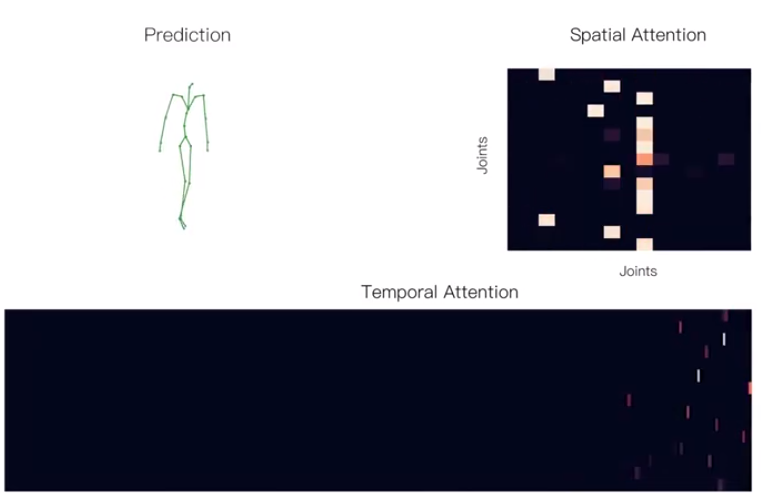
In this paper, we propose a novel Transformer-based architecture for the task of generative modelling of 3D human motion. Previous works commonly rely on RNN-based models considering shorter forecast horizons reaching a stationary and often implausible state quickly. Instead, our focus lies on the generation of plausible future developments over longer time horizons. To mitigate the issue of convergence to a static pose, we propose a novel architecture that leverages the recently proposed self-attention concept. The task of 3D motion prediction is inherently spatio-temporal and thus the proposed model learns high dimensional embeddings for skeletal joints followed by a decoupled temporal and spatial self-attention mechanism. This allows the model to access past information directly and to capture spatio-temporal dependencies explicitly. We show empirically that this reduces error accumulation over time and allows for the generation of perceptually plausible motion sequences over long time horizons up to 20 seconds as well as accurate short-term predictions.