Vision-based Engagement Detection in Virtual Reality

PubDate: Sep 2016
Teams: Konica Minolta Laboratory;Ryerosn University;Stanford Universit
Writers: Ghassem Tofighi, Kaamraan Raahemifar, Maria Frank, Haisong Gu
PDF: Vision-based Engagement Detection in Virtual Reality
Abstract
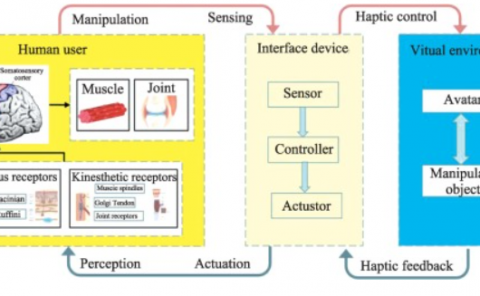
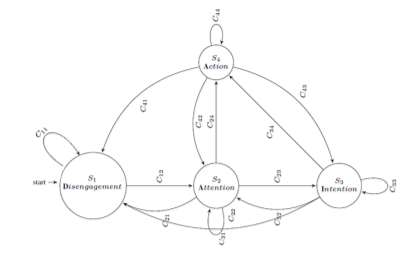
User engagement modeling for manipulating actions in vision-based interfaces is one of the most important case studies of user mental state detection. In a Virtual Reality environment that employs camera sensors to recognize human activities, we have to know when user intends to perform an action and when not. Without a proper algorithm for recognizing engagement status, any kind of activities could be interpreted as manipulating actions, called “Midas Touch” problem. Baseline approach for solving this problem is activating gesture recognition system using some focus gestures such as waiving or raising hand. However, a desirable natural user interface should be able to understand user’s mental status automatically. In this paper, a novel multi-modal model for engagement detection, DAIA, is presented. using DAIA, the spectrum of mental status for performing an action is quantized in a finite number of engagement states. For this purpose, a Finite State Transducer (FST) is designed. This engagement framework shows how to integrate multi-modal information from user biometric data streams such as 2D and 3D imaging. FST is employed to make the state transition smoothly using combination of several boolean expressions. Our FST true detection rate is 92.3% in total for four different states. Results also show FST can segment user hand gestures more robustly.