Training Deep Neural Networks to Detect Repeatable 2D Features Using Large Amounts of 3D World Capture Data

PubDate: Dec 2019
Teams: University of California
Writers: Alexander Mai, Joseph Menke, Allen Yang
Abstract
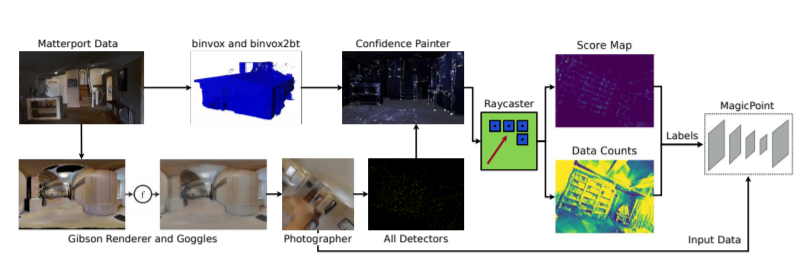
Image space feature detection is the act of selecting points or parts of an image that are easy to distinguish from the surrounding image region. By combining a repeatable point detection with a descriptor, parts of an image can be matched with one another, which is useful in applications like estimating pose from camera input or rectifying images. Recently, precise indoor tracking has started to become important for Augmented and Virtual reality as it is necessary to allow positioning of a headset in 3D space without the need for external tracking devices. Several modern feature detectors use homographies to simulate different viewpoints, not only to train feature detection and description, but test them as well. The problem is that, often, views of indoor spaces contain high depth disparity. This makes the approximation that a homography applied to an image represents a viewpoint change inaccurate. We claim that in order to train detectors to work well in indoor environments, they must be robust to this type of geometry, and repeatable under true viewpoint change instead of homographies. Here we focus on the problem of detecting repeatable feature locations under true viewpoint change. To this end, we generate labeled 2D images from a photo-realistic 3D dataset. These images are used for training a neural network based feature detector. We further present an algorithm for automatically generating labels of repeatable 2D features, and present a fast, easy to use test algorithm for evaluating a detector in an 3D environment.