Audio- and Gaze-driven Facial Animation of Codec Avatars

PubDate: Aug 2020
Teams: Facebook Reality Labs;University of Bonn
Writers: Alexander Richard, Colin Lea, Shugao Ma, Juergen Gall, Fernando de la Torre, Yaser Sheikh
PDF: Audio- and Gaze-driven Facial Animation of Codec Avatars
Abstract
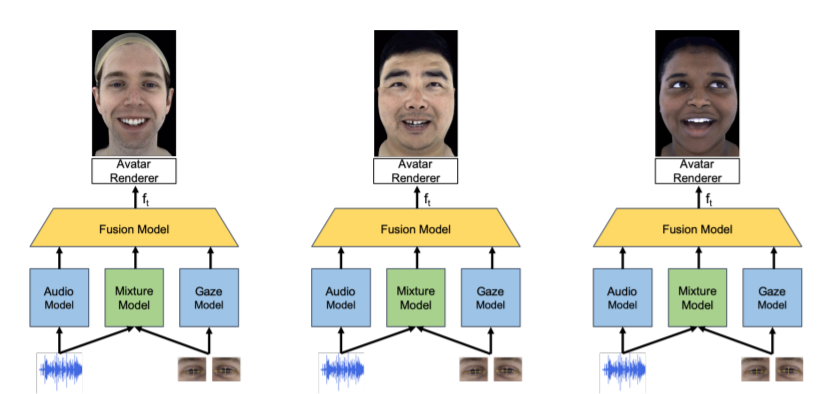
Codec Avatars are a recent class of learned, photorealistic face models that accurately represent the geometry and texture of a person in 3D (i.e., for virtual reality), and are almost indistinguishable from video. In this paper we describe the first approach to animate these parametric models in real-time which could be deployed on commodity virtual reality hardware using audio and/or eye tracking. Our goal is to display expressive conversations between individuals that exhibit important social signals such as laughter and excitement solely from latent cues in our lossy input signals. To this end we collected over 5 hours of high frame rate 3D face scans across three participants including traditional neutral speech as well as expressive and conversational speech. We investigate a multimodal fusion approach that dynamically identifies which sensor encoding should animate which parts of the face at any time. See the supplemental video which demonstrates our ability to generate full face motion far beyond the typically neutral lip articulations seen in competing work: this https URL