Adaptive clustering: reducing the computational costs of distributed (hydrological) modelling by exploiting time-variable similarity among model elements

PubDate: Sep 2020
Teams: Karlsruhe Institute of Technology ;
Writers: Uwe Ehret1, Rik van Pruijssen1, Marina Bortoli1, Ralf Loritz1, Elnaz Azmi2, and Erwin Zehe
Abstract
In this paper we propose adaptive clustering as a new method for reducing the computational efforts of distributed modelling. It consists of identifying similar-acting model elements during runtime, clustering them, running the model for just a few representatives per cluster, and mapping their results to the remaining model elements in the cluster. Key requirements for the application of adaptive clustering are the existence of (i) many model elements with (ii) comparable structural and functional properties and (iii) only weak interaction (e.g. hill slopes, subcatchments, or surface grid elements in hydrological and land surface models). The clustering of model elements must not only consider their time-invariant structural and functional properties but also their current state and forcing, as all these aspects influence their current functioning. Joining model elements into clusters is therefore a continuous task during model execution rather than a one-time exercise that can be done beforehand. Adaptive clustering takes this into account by continuously checking the clustering and re-clustering when necessary.
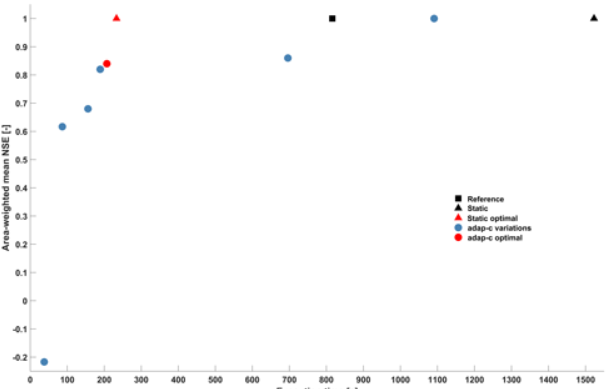
We explain the steps of adaptive clustering and provide a proof of concept at the example of a distributed, conceptual hydrological model fit to the Attert basin in Luxembourg. The clustering is done based on normalised and binned transformations of model element states and fluxes. Analysing a 5-year time series of these transformed states and fluxes revealed that many model elements act very similarly, and the degree of similarity varies strongly with time, indicating the potential for adaptive clustering to save computation time. Compared to a standard, full-resolution model run used as a virtual reality “truth”, adaptive clustering indeed reduced computation time by 75 %, while modelling quality, expressed as the Nash–Sutcliffe efficiency of subcatchment runoff, declined from 1 to 0.84. Based on this proof-of-concept application, we believe that adaptive clustering is a promising tool for reducing the computation time of distributed models. Being adaptive, it integrates and enhances existing methods of static grouping of model elements, such as lumping or grouped response units (GRUs). It is compatible with existing dynamical methods such as adaptive time stepping or adaptive gridding and, unlike the latter, does not require adjacency of the model elements to be joined.
As a welcome side effect, adaptive clustering can be used for system analysis; in our case, analysing the space–time patterns of clustered model elements confirmed that the hydrological functioning of the Attert catchment is mainly controlled by the spatial patterns of geology and precipitation.