Semantic Segmentation of the Eye With a Lightweight Deep Network and Shape Correction

PubDate: July 2020
Teams: Chonnam National University
Writers: Van Thong Huynh; Hyung-Jeong Yang; Guee-Sang Lee; Soo-Hyung Kim
PDF: Semantic Segmentation of the Eye With a Lightweight Deep Network and Shape Correction
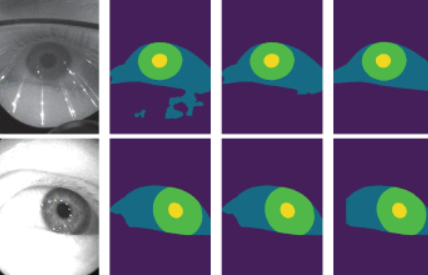
Abstract
This paper presents a method to address the multi-class eye segmentation problem which is an essential step for gaze tracking or applying a biometric system in the virtual reality environment. Our system can run on the resource-constrained environments, such as mobile, embedded devices for real-time inference, while still ensuring the accuracy. To achieve those ends, we deployed the system with three major stages: obtain a grayscale image from the input, divide the image into three distinct eye regions with a deep network, and refine the results with image processing techniques. The deep network is built upon an encoder-decoder scheme with depthwise separation convolution for the low-resource systems. Image processing is accomplished based on the geometric properties of the eye to remove incorrect regions as well as to correct the shape of the eye. The experiments were conducted using OpenEDS, a large dataset of eye images captured with a head-mounted display with two synchronized eye-facing cameras. We achieved a mean intersection over union (mIoU) of 94.91% with a model of size 0.4 megabytes and 16.56 seconds to iterate over the test set of 1,440 images.
