Extracting Specific Voice from Mixed Audio Source

PubDate: December 2019
Teams: LINE Corporation
Writers: Kunihiko Sato
PDF: Extracting Specific Voice from Mixed Audio Source
Abstract
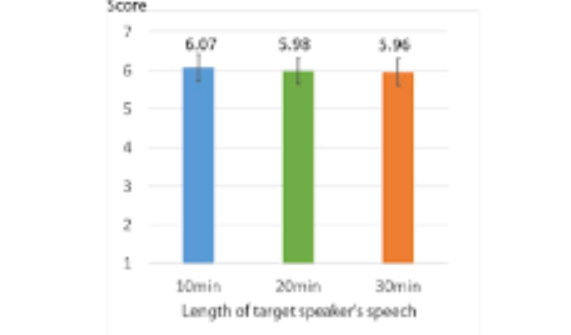
We propose auditory diminished reality by a deep neural network (DNN) extracting a single speech signal from a mixture of sounds containing other speakers and background noise. To realize the proposed DNN, we introduce a new dataset comprised of multi-speakers and environment noises. We conduct evaluations for measuring the source separation quality of the DNN. Additionally, we compare the separation quality of models learned with different amounts of training data. As a result, we found there is no significant difference in the separation quality between 10 and 30 minutes of the target speaker’s speech length for training data.