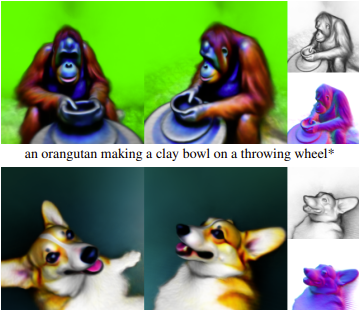
DREAMFUSION: TEXT-TO-3D USING 2D DIFFUSION

PubDate: Sep 2022
Teams: Google Research, 2UC Berkeley
Writers: Ben Poole1, Ajay Jain2, Jonathan T. Barron1, Ben Mildenhall1
PDF: DREAMFUSION: TEXT-TO-3D USING 2D DIFFUSION
Abstract
Recent breakthroughs in text-to-image synthesis have been driven by diffusion models trained on billions of image-text pairs. Adapting this approach to 3D synthesis would require large-scale datasets of labeled 3D data and efficient architectures for denoising 3D data, neither of which currently exist. In this work, we circumvent these limitations by using a pretrained 2D text-to-image diffusion model to perform text-to-3D synthesis. We introduce a loss based on probability density distillation that enables the use of a 2D diffusion model as a prior for optimization of a parametric image generator. Using this loss in a DeepDream-like procedure, we optimize a randomly-initialized 3D model (a Neural Radiance Field, or NeRF) via gradient descent such that its 2D renderings from random angles achieve a low loss. The resulting 3D model of the given text can be viewed from any angle, relit by arbitrary illumination, or composited into any 3D environment. Our approach requires no 3D training data and no modifications to the image diffusion model, demonstrating the effectiveness of pretrained image diffusion models as priors. See dreamfusion3d.github.io for a more immersive view into our 3D results.